 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Heterogeneous Model Merging
Dec 29, 2024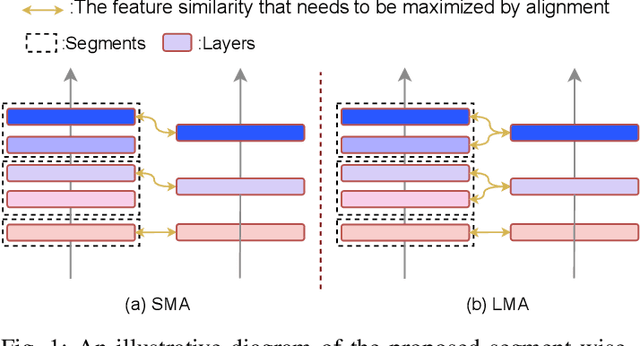



Model merging has attracted significant attention as a powerful paradigm for model reuse, facilitating the integration of task-specific models into a singular, versatile framework endowed with multifarious capabilities. Previous studies, predominantly utilizing methods such as Weight Average (WA), have shown that model merging can effectively leverage pretrained models without the need for laborious retraining. However, the inherent heterogeneity among models poses a substantial constraint on its applicability, particularly when confronted with discrepancies in model architectures. To overcome this challenge, we propose an innovative model merging framework designed for heterogeneous models, encompassing both depth and width heterogeneity. To address depth heterogeneity, we introduce a layer alignment strategy that harmonizes model layers by segmenting deeper models, treating consecutive layers with similar representations as a cohesive segment, thus enabling the seamless merging of models with differing layer depths. For width heterogeneity, we propose a novel elastic neuron zipping algorithm that projects the weights from models of varying widths onto a common dimensional space, eliminating the need for identical widths. Extensive experiments validate the efficacy of these proposed methods, demonstrating that the merging of structurally heterogeneous models can achieve performance levels comparable to those of homogeneous merging, across both vision and NLP tasks. Our code is publicly available at https://github.com/zju-vipa/training_free_heterogeneous_model_merging.
Training-Free Pretrained Model Merging
Mar 15, 2024
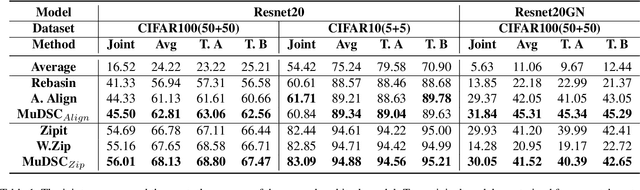
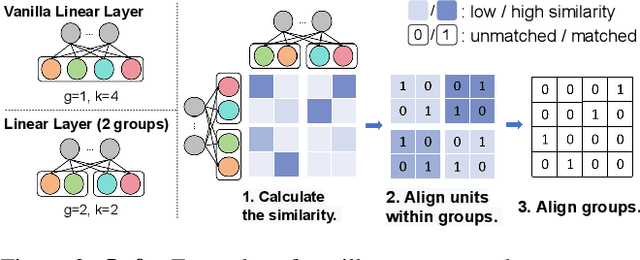
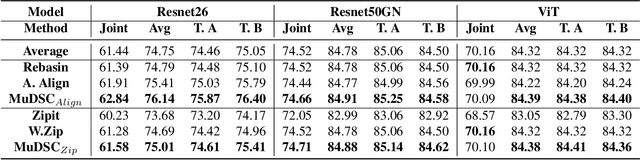
Recently, model merging techniques have surfaced as a solution to combine multiple single-talent models into a single multi-talent model. However, previous endeavors in this field have either necessitated additional training or fine-tuning processes, or require that the models possess the same pre-trained initialization. In this work, we identify a common drawback in prior works w.r.t. the inconsistency of unit similarity in the weight space and the activation space. To address this inconsistency, we propose an innovative model merging framework, coined as merging under dual-space constraints (MuDSC). Specifically, instead of solely maximizing the objective of a single space, we advocate for the exploration of permutation matrices situated in a region with a unified high similarity in the dual space, achieved through the linear combination of activation and weight similarity matrices. In order to enhance usability, we have also incorporated adaptations for group structure, including Multi-Head Attention and Group Normalization. Comprehensive experimental comparisons demonstrate that MuDSC can significantly boost the performance of merged models with various task combinations and architectures. Furthermore, the visualization of the merged model within the multi-task loss landscape reveals that MuDSC enables the merged model to reside in the overlapping segment, featuring a unified lower loss for each task. Our code is publicly available at https://github.com/zju-vipa/training_free_model_merging.
ModelGiF: Gradient Fields for Model Functional Distance
Sep 20, 2023


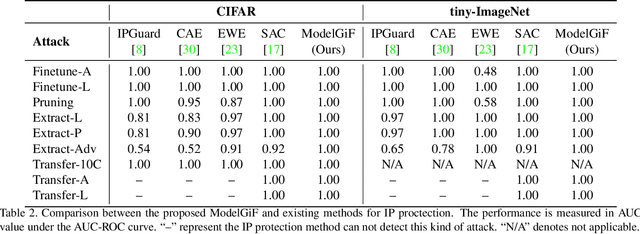
The last decade has witnessed the success of deep learning and the surge of publicly released trained models, which necessitates the quantification of the model functional distance for various purposes. However, quantifying the model functional distance is always challenging due to the opacity in inner workings and the heterogeneity in architectures or tasks. Inspired by the concept of "field" in physics, in this work we introduce Model Gradient Field (abbr. ModelGiF) to extract homogeneous representations from the heterogeneous pre-trained models. Our main assumption underlying ModelGiF is that each pre-trained deep model uniquely determines a ModelGiF over the input space. The distance between models can thus be measured by the similarity between their ModelGiFs. We validate the effectiveness of the proposed ModelGiF with a suite of testbeds, including task relatedness estimation, intellectual property protection, and model unlearning verification. Experimental results demonstrate the versatility of the proposed ModelGiF on these tasks, with significantly superiority performance to state-of-the-art competitors. Codes are available at https://github.com/zju-vipa/modelgif.
Lookaround Optimizer: $k$ steps around, 1 step average
Jun 13, 2023Weight Average (WA) is an active research topic due to its simplicity in ensembling deep networks and the effectiveness in promoting generalization. Existing weight average approaches, however, are often carried out along only one training trajectory in a post-hoc manner (i.e., the weights are averaged after the entire training process is finished), which significantly degrades the diversity between networks and thus impairs the effectiveness in ensembling. In this paper, inspired by weight average, we propose Lookaround, a straightforward yet effective SGD-based optimizer leading to flatter minima with better generalization. Specifically, Lookaround iterates two steps during the whole training period: the around step and the average step. In each iteration, 1) the around step starts from a common point and trains multiple networks simultaneously, each on transformed data by a different data augmentation, and 2) the average step averages these trained networks to get the averaged network, which serves as the starting point for the next iteration. The around step improves the functionality diversity while the average step guarantees the weight locality of these networks during the whole training, which is essential for WA to work. We theoretically explain the superiority of Lookaround by convergence analysis, and make extensive experiments to evaluate Lookaround on popular benchmarks including CIFAR and ImageNet with both CNNs and ViTs, demonstrating clear superiority over state-of-the-arts. Our code is available at https://github.com/Ardcy/Lookaround.