 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Semantic Segmentation for Large-Scale Point Cloud
Dec 09, 2022



Existing methods for large-scale point cloud semantic segmentation require expensive, tedious and error-prone manual point-wise annotations. Intuitively, weakly supervised training is a direct solution to reduce the cost of labeling. However, for weakly supervised large-scale point cloud semantic segmentation, too few annotations will inevitably lead to ineffective learning of network. We propose an effective weakly supervised method containing two components to solve the above problem. Firstly, we construct a pretext task, \textit{i.e.,} point cloud colorization, with a self-supervised learning to transfer the learned prior knowledge from a large amount of unlabeled point cloud to a weakly supervised network. In this way, the representation capability of the weakly supervised network can be improved by the guidance from a heterogeneous task. Besides, to generate pseudo label for unlabeled data, a sparse label propagation mechanism is proposed with the help of generated class prototypes, which is used to measure the classification confidence of unlabeled point. Our method is evaluated on large-scale point cloud datasets with different scenarios including indoor and outdoor. The experimental results show the large gain against existing weakly supervised and comparable results to fully supervised methods\footnote{Code based on mindspore: https://github.com/dmcv-ecnu/MindSpore\_ModelZoo/tree/main/WS3\_MindSpore}.
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020



This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.
Joint Representation of Multiple Geometric Priors via a Shape Decomposition Model for Single Monocular 3D Pose Estimation
May 31, 2019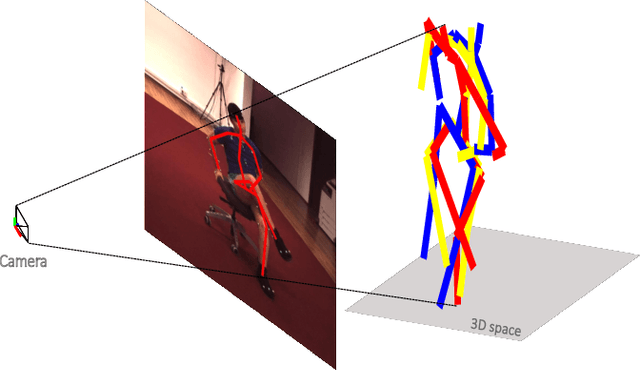
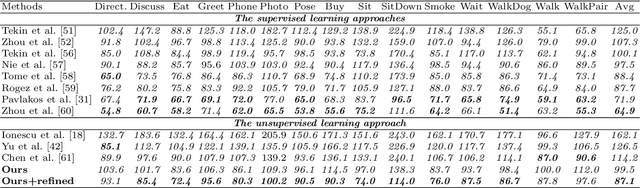
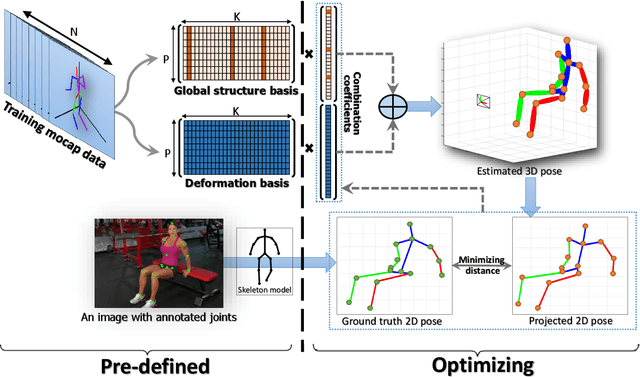
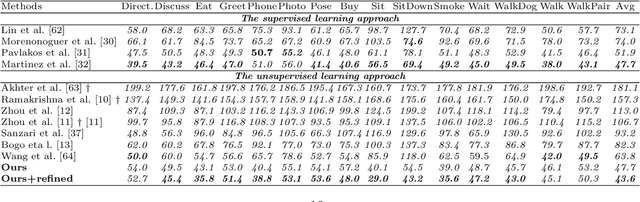
In this paper, we aim to recover the 3D human pose from 2D body joints of a single image. The major challenge in this task is the depth ambiguity since different 3D poses may produce similar 2D poses. Although many recent advances in this problem are found in both unsupervised and supervised learning approaches, the performances of most of these approaches are greatly affected by insufficient diversities and richness of training data. To alleviate this issue, we propose an unsupervised learning approach, which is capable of estimating various complex poses well under limited available training data. Specifically, we propose a Shape Decomposition Model (SDM) in which a 3D pose is considered as the superposition of two parts which are global structure together with some deformations. Based on SDM, we estimate these two parts explicitly by solving two sets of different distributed combination coefficients of geometric priors. In addition, to obtain geometric priors, a joint dictionary learning algorithm is proposed to extract both coarse and fine pose clues simultaneously from limited training data. Quantitative evaluations on several widely used datasets demonstrate that our approach yields better performances over other competitive approaches. Especially, on some categories with more complex deformations, significant improvements are achieved by our approach. Furthermore, qualitative experiments conducted on in-the-wild images also show the effectiveness of the proposed approach.
Bi-GANs-ST for Perceptual Image Super-resolution
Nov 01, 2018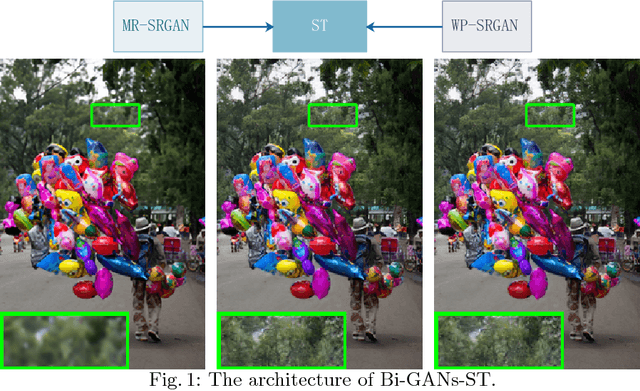
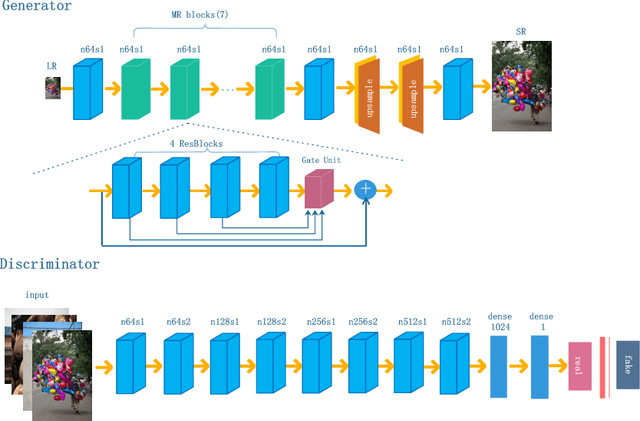
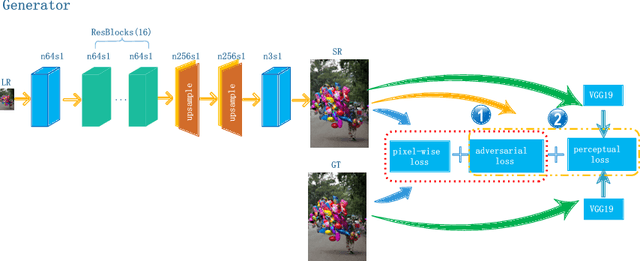
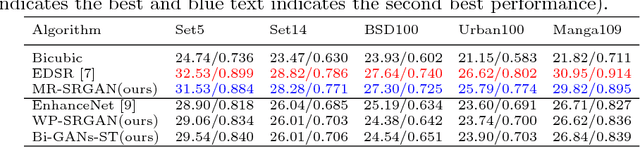
Image quality measurement is a critical problem for image super-resolution (SR) algorithms. Usually, they are evaluated by some well-known objective metrics, e.g., PSNR and SSIM, but these indices cannot provide suitable results in accordance with the perception of human being. Recently, a more reasonable perception measurement has been proposed in [1], which is also adopted by the PIRM-SR 2018 challenge. In this paper, motivated by [1], we aim to generate a high-quality SR result which balances between the two indices, i.e., the perception index and root-mean-square error (RMSE). To do so, we design a new deep SR framework, dubbed Bi-GANs-ST, by integrating two complementary generative adversarial networks (GAN) branches. One is memory residual SRGAN (MR-SRGAN), which emphasizes on improving the objective performance, such as reducing the RMSE. The other is weight perception SRGAN (WP-SRGAN), which obtains the result that favors better subjective perception via a two-stage adversarial training mechanism. Then, to produce final result with excellent perception scores and RMSE, we use soft-thresholding method to merge the results generated by the two GANs. Our method performs well on the perceptual image super-resolution task of the PIRM 2018 challenge. Experimental results on five benchmarks show that our proposal achieves highly competent performance compared with other state-of-the-art methods.
Deep Multi-View Clustering via Multiple Embedding
Aug 19, 2018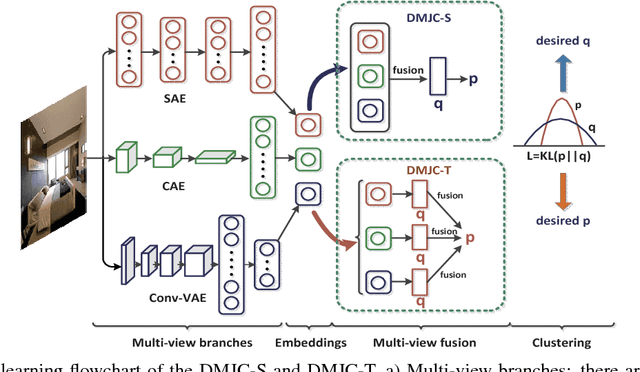
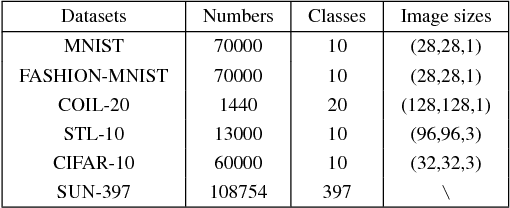
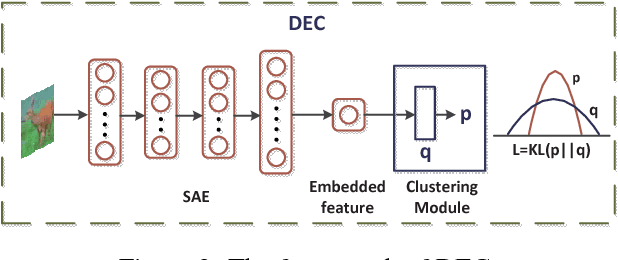
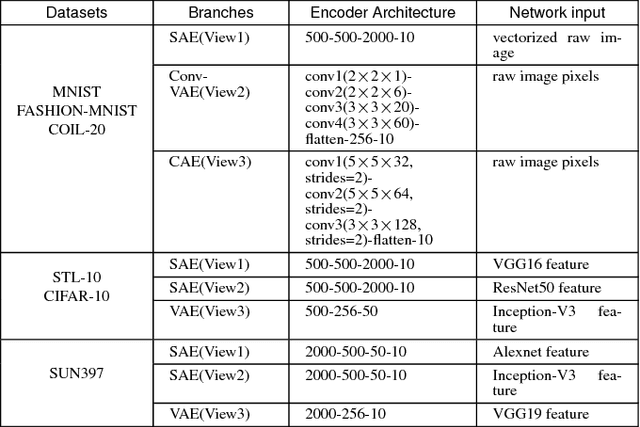
Exploring the information among multiple views usually leads to more promising clustering performance. Most existing multi-view clustering algorithms perform clustering separately: first extracts multiple handcrafted features or deep features, then conducts traditional clustering such as spectral clustering or K-means. However, the learned features may not often work well for clustering. To overcome this problem, we propose the Deep Multi-View Clustering via Multiple Embedding (DMVC-ME), which learns deep embedded features, multi-view fusion mechanism and clustering assignment simultaneously in an end-to-end manner. Specifically, we adopt a KL divergence to refine the soft clustering assignment with the help of a multi-view fused target distribution. The parameters are updated via an efficient alternative optimization scheme. As a result, more clustering-friendly features can be learned and the complementary traits among different views can be well captured. We demonstrate the effectiveness of our approach on several challenging image datasets, where significant superiority can be found over single/multi-view baselines and the state-of-the-art multi-view clustering methods.
An Effective Unconstrained Correlation Filter and Its Kernelization for Face Recognition
Mar 25, 2016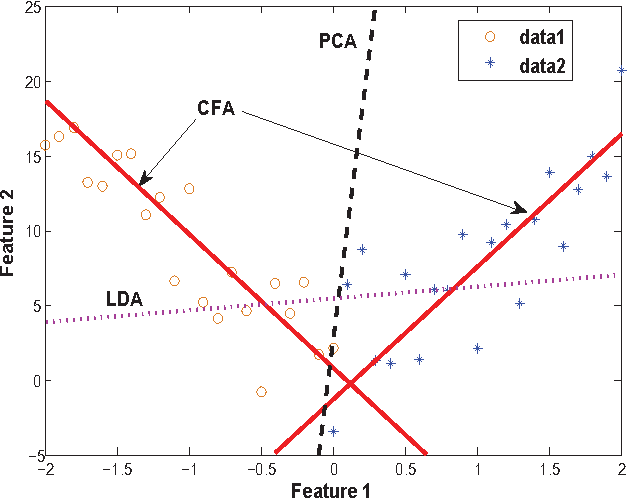
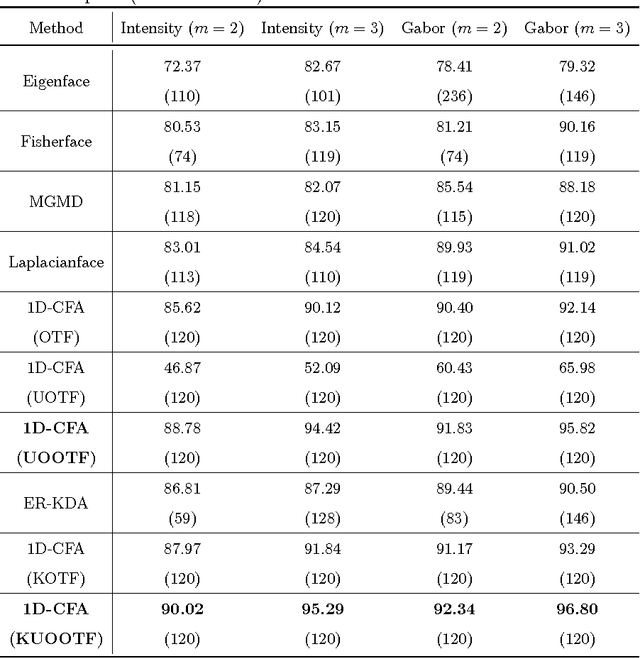
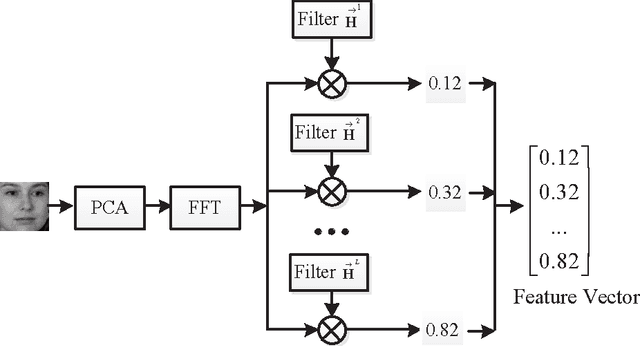
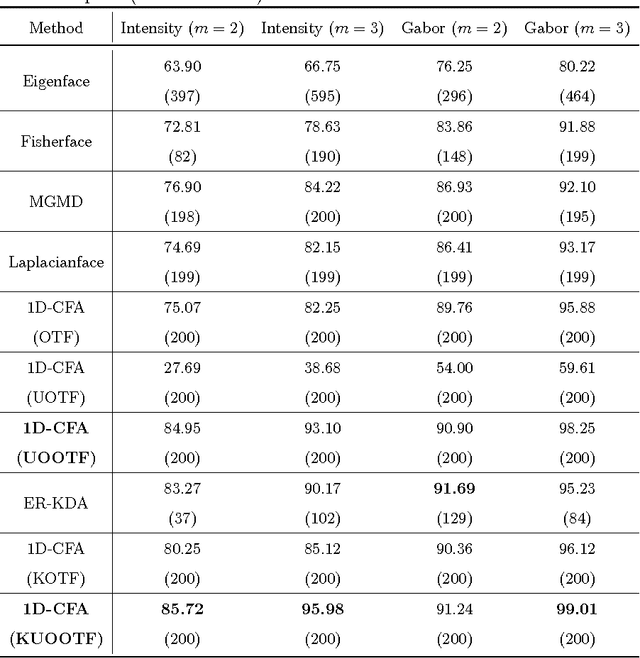
In this paper, an effective unconstrained correlation filter called Uncon- strained Optimal Origin Tradeoff Filter (UOOTF) is presented and applied to robust face recognition. Compared with the conventional correlation filters in Class-dependence Feature Analysis (CFA), UOOTF improves the overall performance for unseen patterns by removing the hard constraints on the origin correlation outputs during the filter design. To handle non-linearly separable distributions between different classes, we further develop a non- linear extension of UOOTF based on the kernel technique. The kernel ex- tension of UOOTF allows for higher flexibility of the decision boundary due to a wider range of non-linearity properties. Experimental results demon- strate the effectiveness of the proposed unconstrained correlation filter and its kernelization in the task of face recognition.