 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks-based Hybrid Framework For Predicting Particle Crushing Strength
Jul 26, 2023Graph Neural Networks have emerged as an effective machine learning tool for multi-disciplinary tasks such as pharmaceutical molecule classification and chemical reaction prediction, because they can model non-euclidean relationships between different entities. Particle crushing, as a significant field of civil engineering, describes the breakage of granular materials caused by the breakage of particle fragment bonds under the modeling of numerical simulations, which motivates us to characterize the mechanical behaviors of particle crushing through the connectivity of particle fragments with Graph Neural Networks (GNNs). However, there lacks an open-source large-scale particle crushing dataset for research due to the expensive costs of laboratory tests or numerical simulations. Therefore, we firstly generate a dataset with 45,000 numerical simulations and 900 particle types to facilitate the research progress of machine learning for particle crushing. Secondly, we devise a hybrid framework based on GNNs to predict particle crushing strength in a particle fragment view with the advances of state of the art GNNs. Finally, we compare our hybrid framework against traditional machine learning methods and the plain MLP to verify its effectiveness. The usefulness of different features is further discussed through the gradient attribution explanation w.r.t the predictions. Our data and code are released at https://github.com/doujiang-zheng/GNN-For-Particle-Crushing.
Transition Propagation Graph Neural Networks for Temporal Networks
Apr 15, 2023
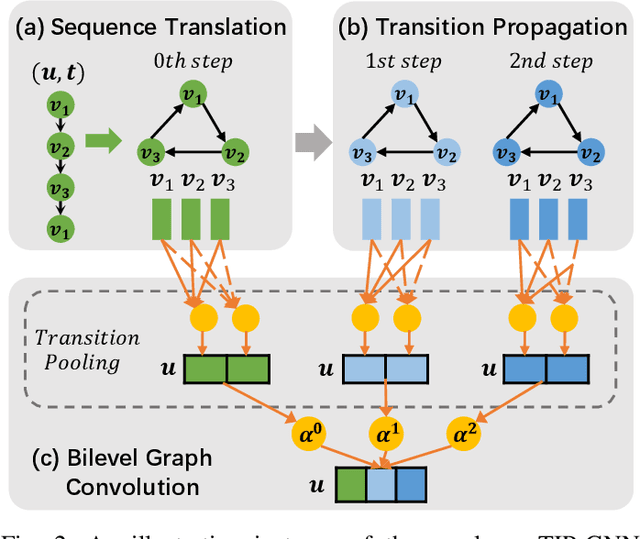
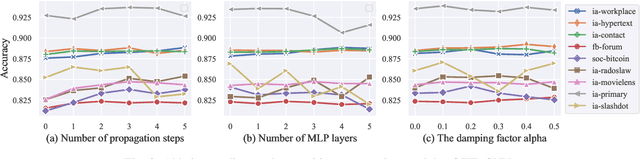
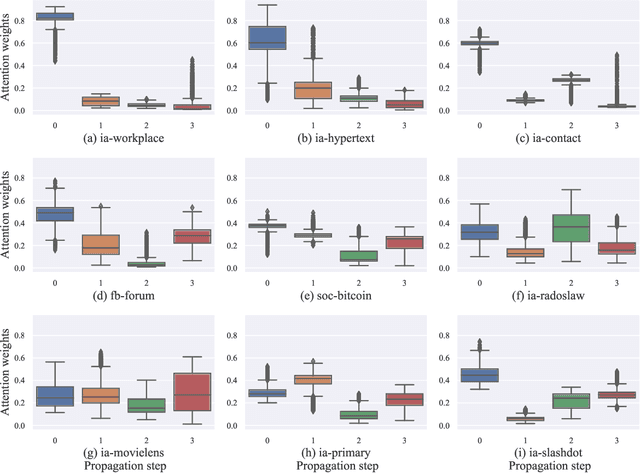
Researchers of temporal networks (e.g., social networks and transaction networks) have been interested in mining dynamic patterns of nodes from their diverse interactions. Inspired by recently powerful graph mining methods like skip-gram models and Graph Neural Networks (GNNs), existing approaches focus on generating temporal node embeddings sequentially with nodes' sequential interactions. However, the sequential modeling of previous approaches cannot handle the transition structure between nodes' neighbors with limited memorization capacity. Detailedly, an effective method for the transition structures is required to both model nodes' personalized patterns adaptively and capture node dynamics accordingly. In this paper, we propose a method, namely Transition Propagation Graph Neural Networks (TIP-GNN), to tackle the challenges of encoding nodes' transition structures. The proposed TIP-GNN focuses on the bilevel graph structure in temporal networks: besides the explicit interaction graph, a node's sequential interactions can also be constructed as a transition graph. Based on the bilevel graph, TIP-GNN further encodes transition structures by multi-step transition propagation and distills information from neighborhoods by a bilevel graph convolution. Experimental results over various temporal networks reveal the efficiency of our TIP-GNN, with at most 7.2\% improvements of accuracy on temporal link prediction. Extensive ablation studies further verify the effectiveness and limitations of the transition propagation module. Our code is available at \url{https://github.com/doujiang-zheng/TIP-GNN}.
Generalization Matters: Loss Minima Flattening via Parameter Hybridization for Efficient Online Knowledge Distillation
Mar 26, 2023



Most existing online knowledge distillation(OKD) techniques typically require sophisticated modules to produce diverse knowledge for improving students' generalization ability. In this paper, we strive to fully utilize multi-model settings instead of well-designed modules to achieve a distillation effect with excellent generalization performance. Generally, model generalization can be reflected in the flatness of the loss landscape. Since averaging parameters of multiple models can find flatter minima, we are inspired to extend the process to the sampled convex combinations of multi-student models in OKD. Specifically, by linearly weighting students' parameters in each training batch, we construct a Hybrid-Weight Model(HWM) to represent the parameters surrounding involved students. The supervision loss of HWM can estimate the landscape's curvature of the whole region around students to measure the generalization explicitly. Hence we integrate HWM's loss into students' training and propose a novel OKD framework via parameter hybridization(OKDPH) to promote flatter minima and obtain robust solutions. Considering the redundancy of parameters could lead to the collapse of HWM, we further introduce a fusion operation to keep the high similarity of students. Compared to the state-of-the-art(SOTA) OKD methods and SOTA methods of seeking flat minima, our OKDPH achieves higher performance with fewer parameters, benefiting OKD with lightweight and robust characteristics. Our code is publicly available at https://github.com/tianlizhang/OKDPH.