 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoPFormer: Concentrating on Prototypical Parts in Vision Transformers for Interpretable Image Recognition
Paper and Code
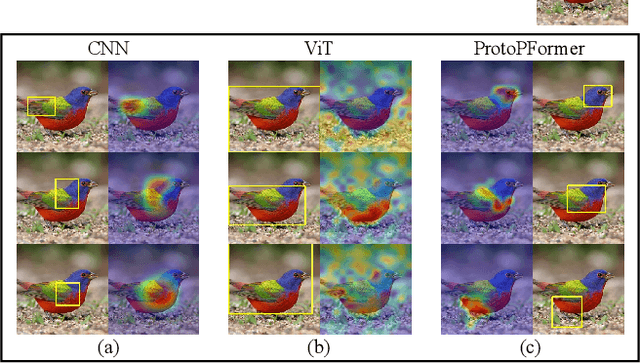
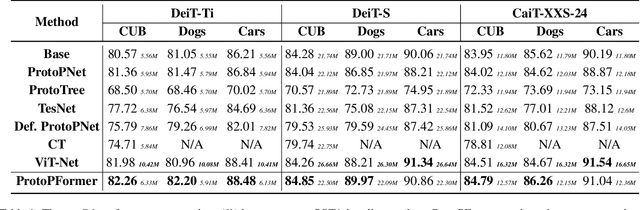
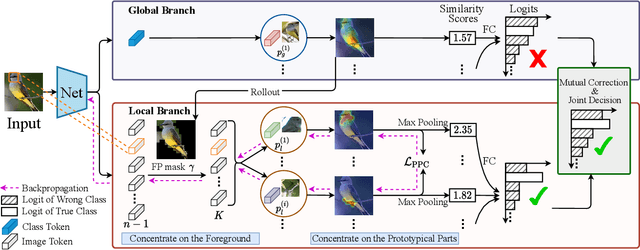
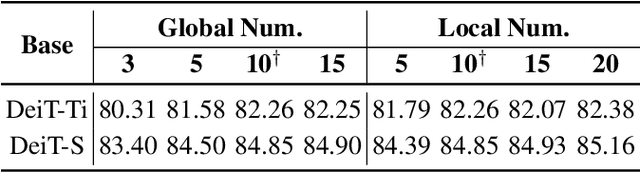
Prototypical part network (ProtoPNet) has drawn wide attention and boosted many follow-up studies due to its self-explanatory property for explainable artificial intelligence (XAI). However, when directly applying ProtoPNet on vision transformer (ViT) backbones, learned prototypes have a ''distraction'' problem: they have a relatively high probability of being activated by the background and pay less attention to the foreground. The powerful capability of modeling long-term dependency makes the transformer-based ProtoPNet hard to focus on prototypical parts, thus severely impairing its inherent interpretability. This paper proposes prototypical part transformer (ProtoPFormer) for appropriately and effectively applying the prototype-based method with ViTs for interpretable image recognition. The proposed method introduces global and local prototypes for capturing and highlighting the representative holistic and partial features of targets according to the architectural characteristics of ViTs. The global prototypes are adopted to provide the global view of objects to guide local prototypes to concentrate on the foreground while eliminating the influence of the background. Afterwards, local prototypes are explicitly supervised to concentrate on their respective prototypical visual parts, increasing the overall interpretability. Extensive experiments demonstrate that our proposed global and local prototypes can mutually correct each other and jointly make final decisions, which faithfully and transparently reason the decision-making processes associatively from the whole and local perspectives, respectively. Moreover, ProtoPFormer consistently achieves superior performance and visualization results over the state-of-the-art (SOTA) prototype-based baselines. Our code has been released at https://github.com/zju-vipa/ProtoPFormer.