 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Concept Trustworthiness in Concept Bottleneck Models
Mar 21, 2024



Concept Bottleneck Models (CBMs), which break down the reasoning process into the input-to-concept mapping and the concept-to-label prediction, have garnered significant attention due to their remarkable interpretability achieved by the interpretable concept bottleneck. However, despite the transparency of the concept-to-label prediction, the mapping from the input to the intermediate concept remains a black box, giving rise to concerns about the trustworthiness of the learned concepts (i.e., these concepts may be predicted based on spurious cues). The issue of concept untrustworthiness greatly hampers the interpretability of CBMs, thereby hindering their further advancement. To conduct a comprehensive analysis on this issue, in this study we establish a benchmark to assess the trustworthiness of concepts in CBMs. A pioneering metric, referred to as concept trustworthiness score, is proposed to gauge whether the concepts are derived from relevant regions. Additionally, an enhanced CBM is introduced, enabling concept predictions to be made specifically from distinct parts of the feature map, thereby facilitating the exploration of their related regions. Besides, we introduce three modules, namely the cross-layer alignment (CLA) module, the cross-image alignment (CIA) module, and the prediction alignment (PA) module, to further enhance the concept trustworthiness within the elaborated CBM. The experiments on five datasets across ten architectures demonstrate that without using any concept localization annotations during training, our model improves the concept trustworthiness by a large margin, meanwhile achieving superior accuracy to the state-of-the-arts. Our code is available at https://github.com/hqhQAQ/ProtoCBM.
M3ED: Multi-modal Multi-scene Multi-label Emotional Dialogue Database
May 09, 2022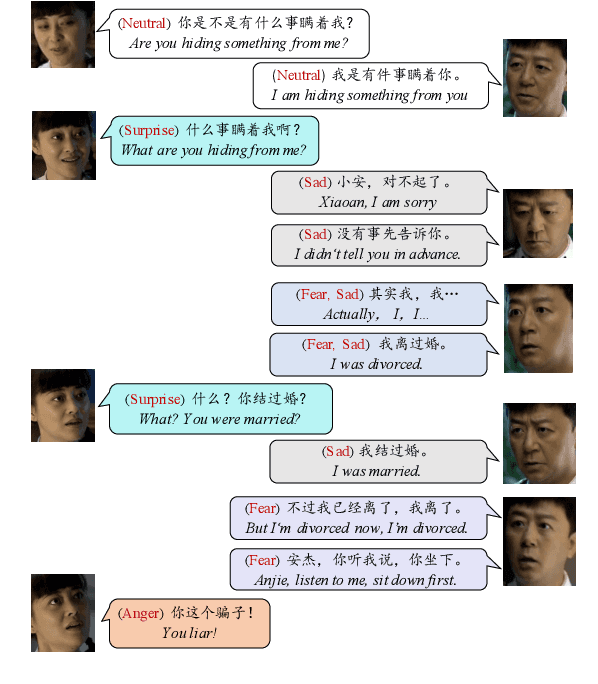
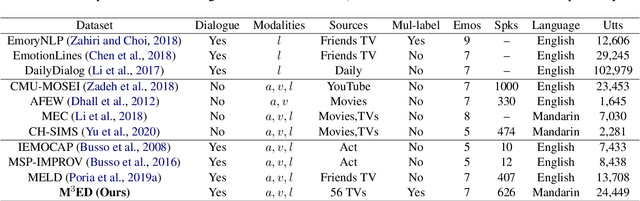
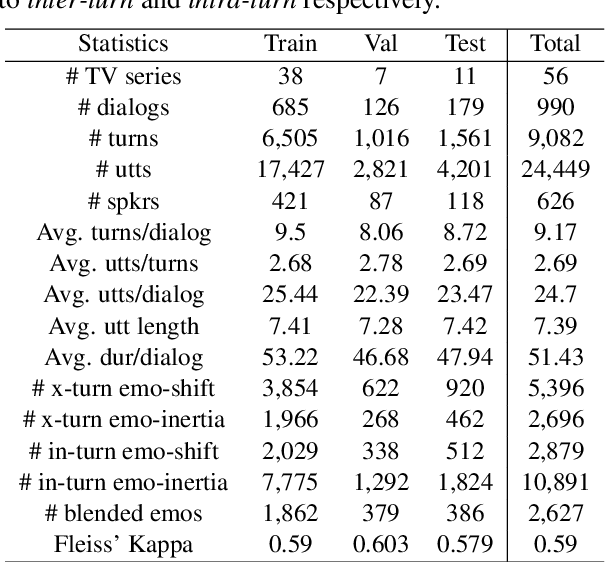
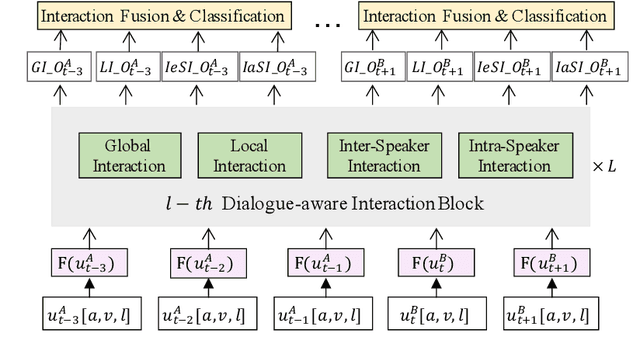
The emotional state of a speaker can be influenced by many different factors in dialogues, such as dialogue scene, dialogue topic, and interlocutor stimulus. The currently available data resources to support such multimodal affective analysis in dialogues are however limited in scale and diversity. In this work, we propose a Multi-modal Multi-scene Multi-label Emotional Dialogue dataset, M3ED, which contains 990 dyadic emotional dialogues from 56 different TV series, a total of 9,082 turns and 24,449 utterances. M3 ED is annotated with 7 emotion categories (happy, surprise, sad, disgust, anger, fear, and neutral) at utterance level, and encompasses acoustic, visual, and textual modalities. To the best of our knowledge, M3ED is the first multimodal emotional dialogue dataset in Chinese. It is valuable for cross-culture emotion analysis and recognition. We apply several state-of-the-art methods on the M3ED dataset to verify the validity and quality of the dataset. We also propose a general Multimodal Dialogue-aware Interaction framework, MDI, to model the dialogue context for emotion recognition, which achieves comparable performance to the state-of-the-art methods on the M3ED. The full dataset and codes are available.
MMGCN: Multimodal Fusion via Deep Graph Convolution Network for Emotion Recognition in Conversation
Jul 14, 2021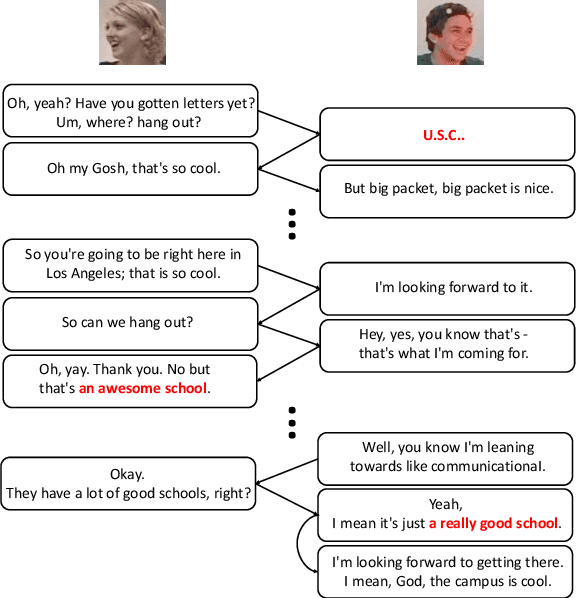
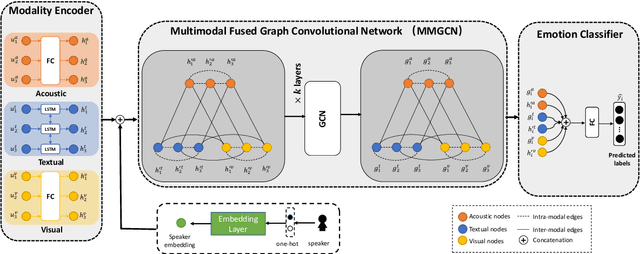
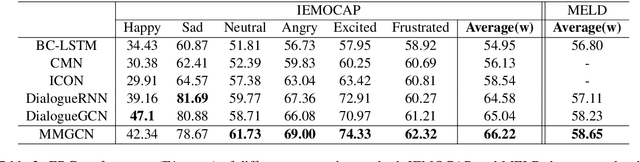
Emotion recognition in conversation (ERC) is a crucial component in affective dialogue systems, which helps the system understand users' emotions and generate empathetic responses. However, most works focus on modeling speaker and contextual information primarily on the textual modality or simply leveraging multimodal information through feature concatenation. In order to explore a more effective way of utilizing both multimodal and long-distance contextual information, we propose a new model based on multimodal fused graph convolutional network, MMGCN, in this work. MMGCN can not only make use of multimodal dependencies effectively, but also leverage speaker information to model inter-speaker and intra-speaker dependency. We evaluate our proposed model on two public benchmark datasets, IEMOCAP and MELD, and the results prove the effectiveness of MMGCN, which outperforms other SOTA methods by a significant margin under the multimodal conversation setting.
Generating Persona Consistent Dialogues by Exploiting Natural Language Inference
Dec 02, 2019
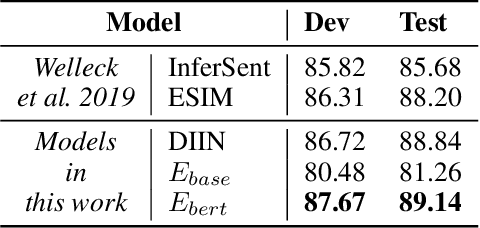
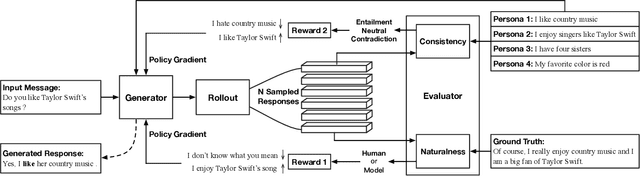
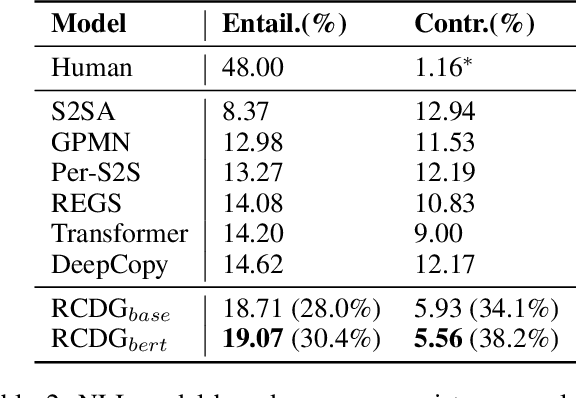
Consistency is one of the major challenges faced by dialogue agents. A human-like dialogue agent should not only respond naturally, but also maintain a consistent persona. In this paper, we exploit the advantages of natural language inference (NLI) technique to address the issue of generating persona consistent dialogues. Different from existing work that re-ranks the retrieved responses through an NLI model, we cast the task as a reinforcement learning problem and propose to exploit the NLI signals from response-persona pairs as rewards for the process of dialogue generation. Specifically, our generator employs an attention-based encoder-decoder to generate persona-based responses. Our evaluator consists of two components: an adversarially trained naturalness module and an NLI based consistency module. Moreover, we use another well-performed NLI model in the evaluation of persona-consistency. Experimental results on both human and automatic metrics, including the model-based consistency evaluation, demonstrate that the proposed approach outperforms strong generative baselines, especially in the persona-consistency of generated responses.
AID: A Benchmark Dataset for Performance Evaluation of Aerial Scene Classification
Aug 18, 2016



Aerial scene classification, which aims to automatically label an aerial image with a specific semantic category, is a fundamental problem for understanding high-resolution remote sensing imagery. In recent years, it has become an active task in remote sensing area and numerous algorithms have been proposed for this task, including many machine learning and data-driven approaches. However, the existing datasets for aerial scene classification like UC-Merced dataset and WHU-RS19 are with relatively small sizes, and the results on them are already saturated. This largely limits the development of scene classification algorithms. This paper describes the Aerial Image Dataset (AID): a large-scale dataset for aerial scene classification. The goal of AID is to advance the state-of-the-arts in scene classification of remote sensing images. For creating AID, we collect and annotate more than ten thousands aerial scene images. In addition, a comprehensive review of the existing aerial scene classification techniques as well as recent widely-used deep learning methods is given. Finally, we provide a performance analysis of typical aerial scene classification and deep learning approaches on AID, which can be served as the baseline results on this benchmark.
Dense v.s. Sparse: A Comparative Study of Sampling Analysis in Scene Classification of High-Resolution Remote Sensing Imagery
Jul 31, 2015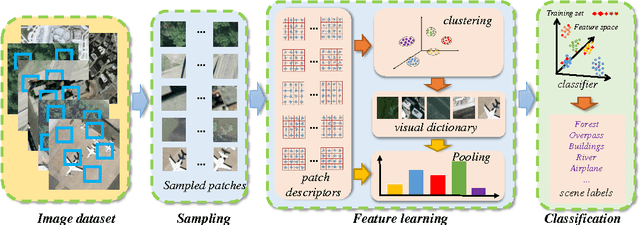
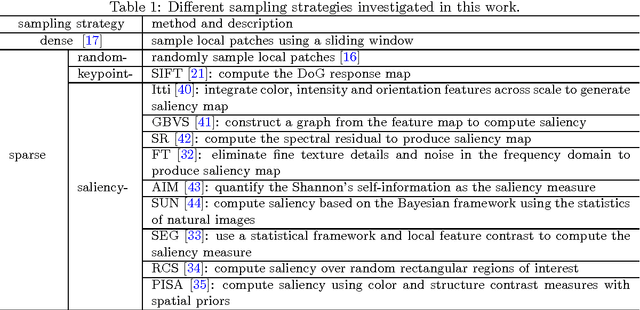

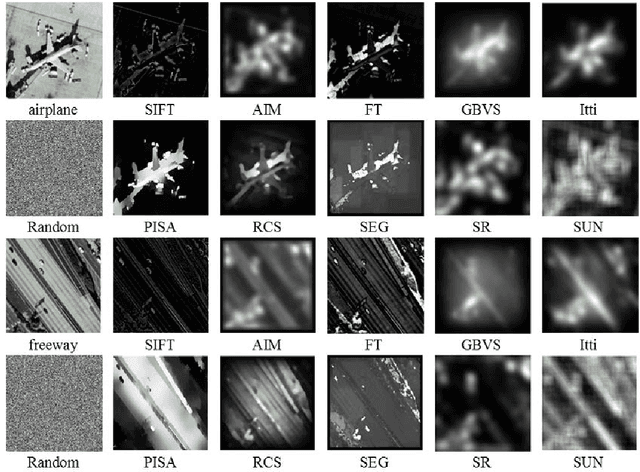
Scene classification is a key problem in the interpretation of high-resolution remote sensing imagery. Many state-of-the-art methods, e.g. bag-of-visual-words model and its variants, the topic models as well as deep learning-based approaches, share similar procedures: patch sampling, feature description/learning and classification. Patch sampling is the first and a key procedure which has a great influence on the results. In the literature, many different sampling strategies have been used, {e.g. dense sampling, random sampling, keypoint-based sampling and saliency-based sampling, etc. However, it is still not clear which sampling strategy is suitable for the scene classification of high-resolution remote sensing images. In this paper, we comparatively study the effects of different sampling strategies under the scenario of scene classification of high-resolution remote sensing images. We divide the existing sampling methods into two types: dense sampling and sparse sampling, the later of which includes random sampling, keypoint-based sampling and various saliency-based sampling proposed recently. In order to compare their performances, we rely on a standard bag-of-visual-words model to construct our testing scheme, owing to their simplicity, robustness and efficiency. The experimental results on two commonly used datasets show that dense sampling has the best performance among all the strategies but with high spatial and computational complexity, random sampling gives better or comparable results than other sparse sampling methods, like the sophisticated multi-scale key-point operators and the saliency-based methods which are intensively studied and commonly used recently.