 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3ED: Multi-modal Multi-scene Multi-label Emotional Dialogue Database
Paper and Code
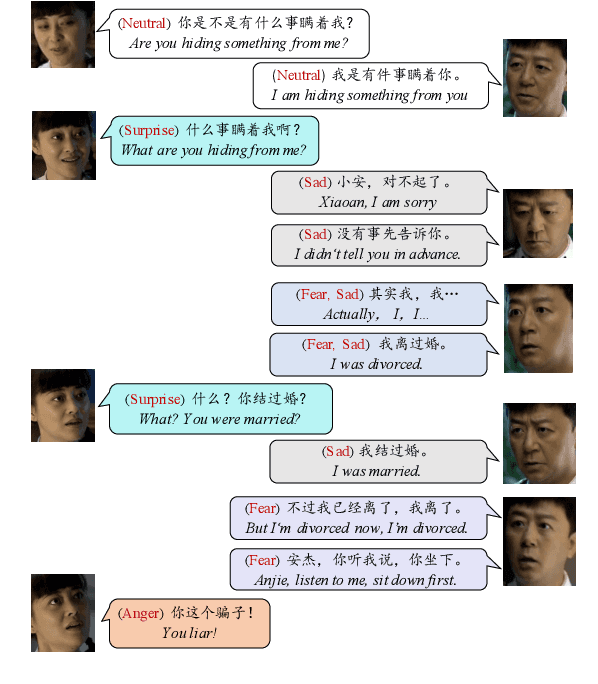
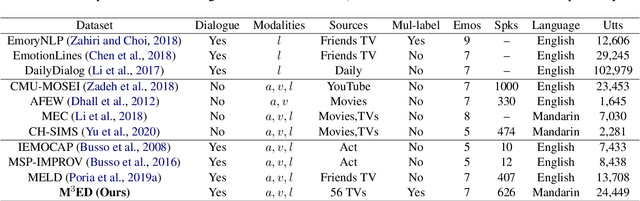
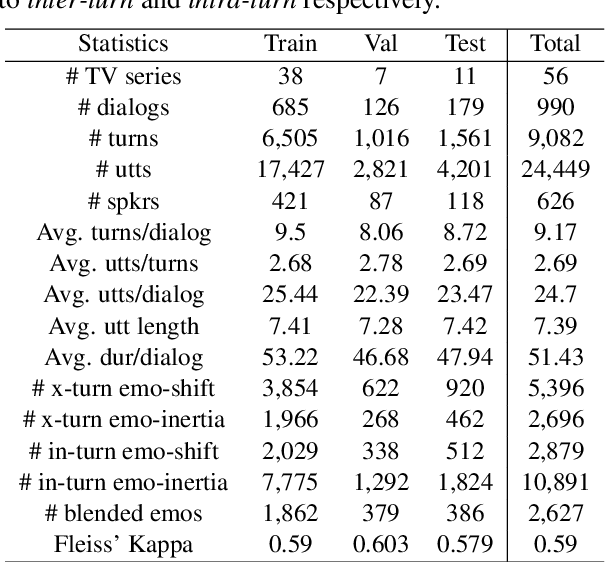
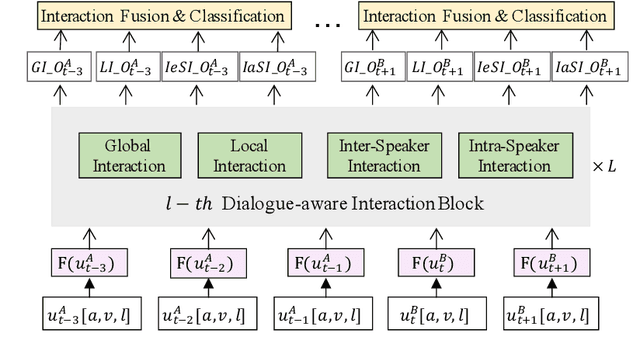
The emotional state of a speaker can be influenced by many different factors in dialogues, such as dialogue scene, dialogue topic, and interlocutor stimulus. The currently available data resources to support such multimodal affective analysis in dialogues are however limited in scale and diversity. In this work, we propose a Multi-modal Multi-scene Multi-label Emotional Dialogue dataset, M3ED, which contains 990 dyadic emotional dialogues from 56 different TV series, a total of 9,082 turns and 24,449 utterances. M3 ED is annotated with 7 emotion categories (happy, surprise, sad, disgust, anger, fear, and neutral) at utterance level, and encompasses acoustic, visual, and textual modalities. To the best of our knowledge, M3ED is the first multimodal emotional dialogue dataset in Chinese. It is valuable for cross-culture emotion analysis and recognition. We apply several state-of-the-art methods on the M3ED dataset to verify the validity and quality of the dataset. We also propose a general Multimodal Dialogue-aware Interaction framework, MDI, to model the dialogue context for emotion recognition, which achieves comparable performance to the state-of-the-art methods on the M3ED. The full dataset and codes are available.