 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESCoT: Towards Interpretable Emotional Support Dialogue Systems
Jun 16, 2024
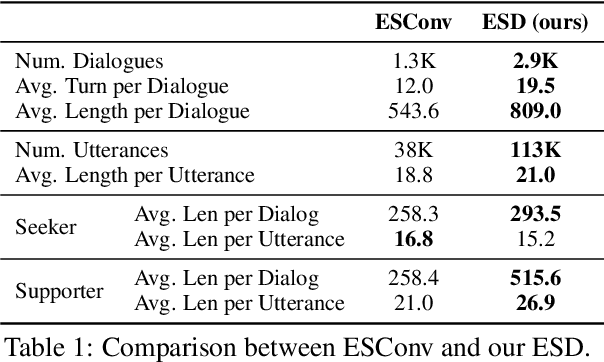

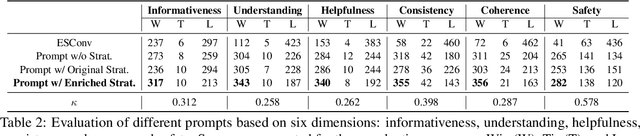
Understanding the reason for emotional support response is crucial for establishing connections between users and emotional support dialogue systems. Previous works mostly focus on generating better responses but ignore interpretability, which is extremely important for constructing reliable dialogue systems. To empower the system with better interpretability, we propose an emotional support response generation scheme, named $\textbf{E}$motion-Focused and $\textbf{S}$trategy-Driven $\textbf{C}$hain-$\textbf{o}$f-$\textbf{T}$hought ($\textbf{ESCoT}$), mimicking the process of $\textit{identifying}$, $\textit{understanding}$, and $\textit{regulating}$ emotions. Specially, we construct a new dataset with ESCoT in two steps: (1) $\textit{Dialogue Generation}$ where we first generate diverse conversation situations, then enhance dialogue generation using richer emotional support strategies based on these situations; (2) $\textit{Chain Supplement}$ where we focus on supplementing selected dialogues with elements such as emotion, stimuli, appraisal, and strategy reason, forming the manually verified chains. Additionally, we further develop a model to generate dialogue responses with better interpretability. We also conduct extensive experiments and human evaluations to validate the effectiveness of the proposed ESCoT and generated dialogue responses. Our data and code are available at $\href{https://github.com/TeigenZhang/ESCoT}{https://github.com/TeigenZhang/ESCoT}$.
Multi-modal Expression Recognition with Ensemble Method
Mar 17, 2023This paper presents our submission to the Expression Classification Challenge of the fifth Affective Behavior Analysis in-the-wild (ABAW) Competition. In our method, multimodal feature combinations extracted by several different pre-trained models are applied to capture more effective emotional information. For these combinations of visual and audio modal features, we utilize two temporal encoders to explore the temporal contextual information in the data. In addition, we employ several ensemble strategies for different experimental settings to obtain the most accurate expression recognition results. Our system achieves the average F1 Score of 0.45774 on the validation set.
Emotion Recognition based on Multi-Task Learning Framework in the ABAW4 Challenge
Jul 25, 2022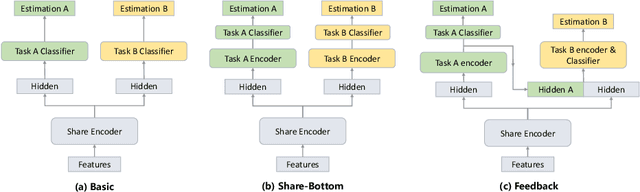



This paper presents our submission to the Multi-Task Learning (MTL) Challenge of the 4th Affective Behavior Analysis in-the-wild (ABAW) competition. Based on visual feature representations, we utilize three types of temporal encoder to capture the temporal context information in the video, including the transformer based encoder, LSTM based encoder and GRU based encoder. With the temporal context-aware representations, we employ multi-task framework to predict the valence, arousal, expression and AU values of the images. In addition, smoothing processing is applied to refine the initial valence and arousal predictions, and a model ensemble strategy is used to combine multiple results from different model setups. Our system achieves the performance of $1.742$ on MTL Challenge validation dataset.
M3ED: Multi-modal Multi-scene Multi-label Emotional Dialogue Database
May 09, 2022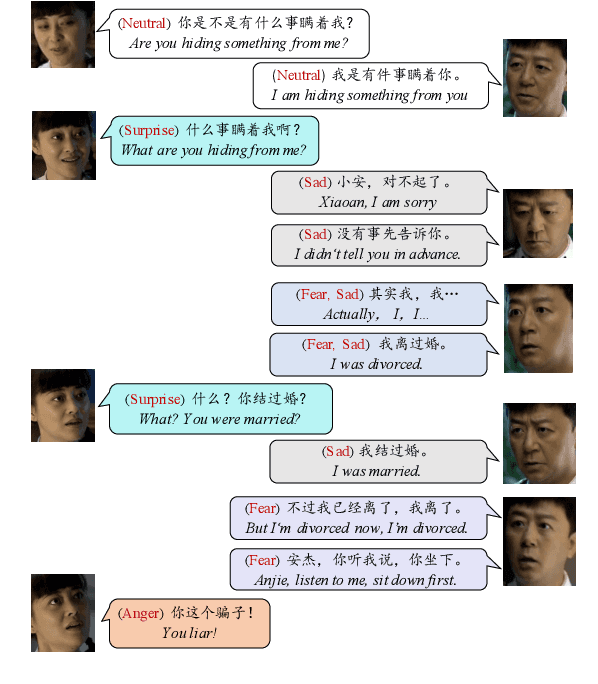
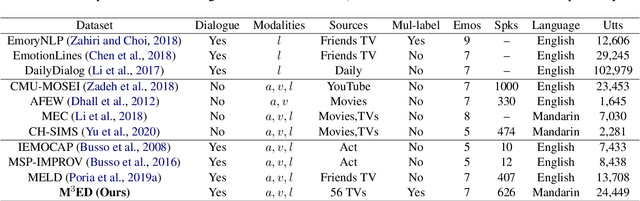
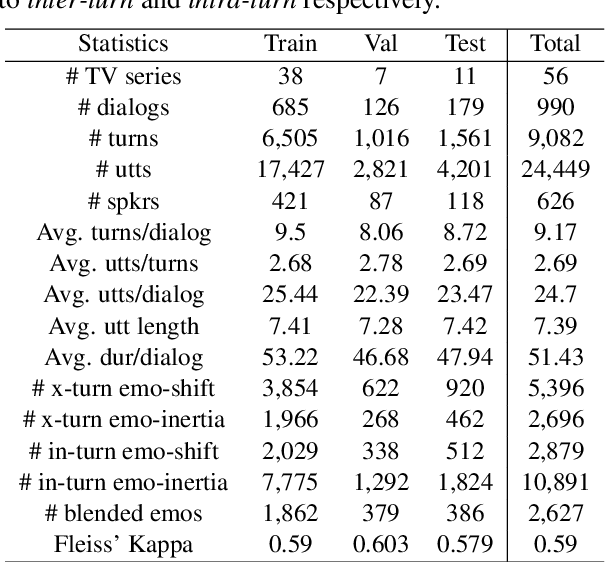
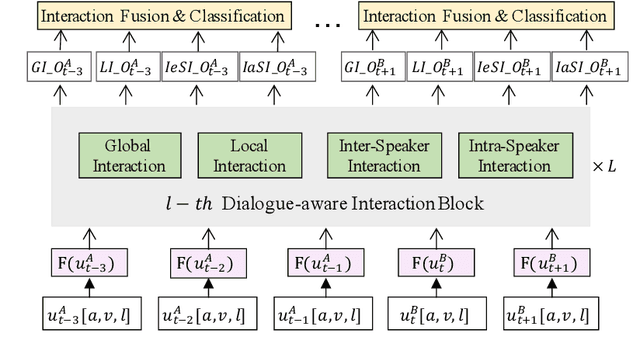
The emotional state of a speaker can be influenced by many different factors in dialogues, such as dialogue scene, dialogue topic, and interlocutor stimulus. The currently available data resources to support such multimodal affective analysis in dialogues are however limited in scale and diversity. In this work, we propose a Multi-modal Multi-scene Multi-label Emotional Dialogue dataset, M3ED, which contains 990 dyadic emotional dialogues from 56 different TV series, a total of 9,082 turns and 24,449 utterances. M3 ED is annotated with 7 emotion categories (happy, surprise, sad, disgust, anger, fear, and neutral) at utterance level, and encompasses acoustic, visual, and textual modalities. To the best of our knowledge, M3ED is the first multimodal emotional dialogue dataset in Chinese. It is valuable for cross-culture emotion analysis and recognition. We apply several state-of-the-art methods on the M3ED dataset to verify the validity and quality of the dataset. We also propose a general Multimodal Dialogue-aware Interaction framework, MDI, to model the dialogue context for emotion recognition, which achieves comparable performance to the state-of-the-art methods on the M3ED. The full dataset and codes are available.