 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Recognition based on Multi-Task Learning Framework in the ABAW4 Challenge
Paper and Code
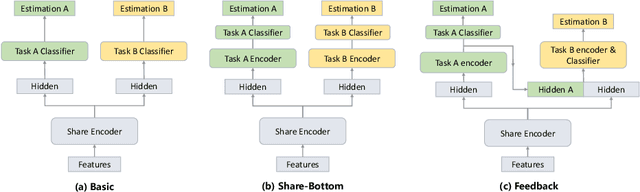



This paper presents our submission to the Multi-Task Learning (MTL) Challenge of the 4th Affective Behavior Analysis in-the-wild (ABAW) competition. Based on visual feature representations, we utilize three types of temporal encoder to capture the temporal context information in the video, including the transformer based encoder, LSTM based encoder and GRU based encoder. With the temporal context-aware representations, we employ multi-task framework to predict the valence, arousal, expression and AU values of the images. In addition, smoothing processing is applied to refine the initial valence and arousal predictions, and a model ensemble strategy is used to combine multiple results from different model setups. Our system achieves the performance of $1.742$ on MTL Challenge validation dataset.