 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Expression Recognition with Ensemble Method
Mar 17, 2023This paper presents our submission to the Expression Classification Challenge of the fifth Affective Behavior Analysis in-the-wild (ABAW) Competition. In our method, multimodal feature combinations extracted by several different pre-trained models are applied to capture more effective emotional information. For these combinations of visual and audio modal features, we utilize two temporal encoders to explore the temporal contextual information in the data. In addition, we employ several ensemble strategies for different experimental settings to obtain the most accurate expression recognition results. Our system achieves the average F1 Score of 0.45774 on the validation set.
Emotion Recognition based on Multi-Task Learning Framework in the ABAW4 Challenge
Jul 25, 2022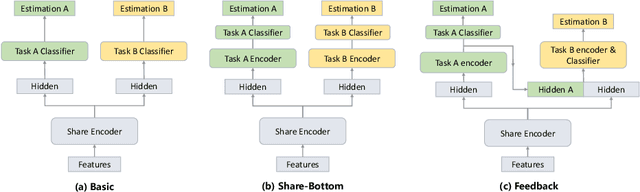



This paper presents our submission to the Multi-Task Learning (MTL) Challenge of the 4th Affective Behavior Analysis in-the-wild (ABAW) competition. Based on visual feature representations, we utilize three types of temporal encoder to capture the temporal context information in the video, including the transformer based encoder, LSTM based encoder and GRU based encoder. With the temporal context-aware representations, we employ multi-task framework to predict the valence, arousal, expression and AU values of the images. In addition, smoothing processing is applied to refine the initial valence and arousal predictions, and a model ensemble strategy is used to combine multiple results from different model setups. Our system achieves the performance of $1.742$ on MTL Challenge validation dataset.
Facial Action Unit Recognition With Multi-models Ensembling
Mar 24, 2022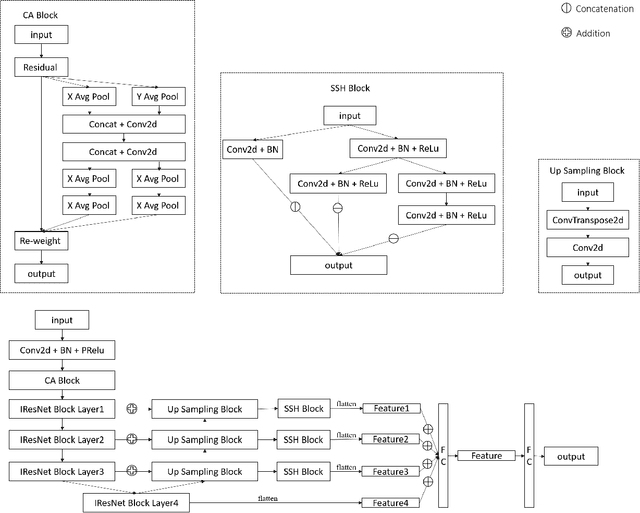
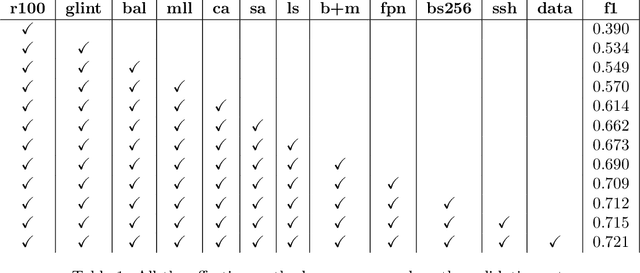


The Affective Behavior Analysis in-the-wild (ABAW) 2022 Competition gives Affective Computing a large promotion. In this paper, we present our method of AU challenge in this Competition. We use improved IResnet100 as backbone. Then we train AU dataset in Aff-Wild2 on three pertained models pretrained by our private au and expression dataset, and Glint360K respectively. Finally, we ensemble the results of our models. We achieved F1 score (macro) 0.731 on AU validation set.