 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense v.s. Sparse: A Comparative Study of Sampling Analysis in Scene Classification of High-Resolution Remote Sensing Imagery
Paper and Code
Jul 31, 2015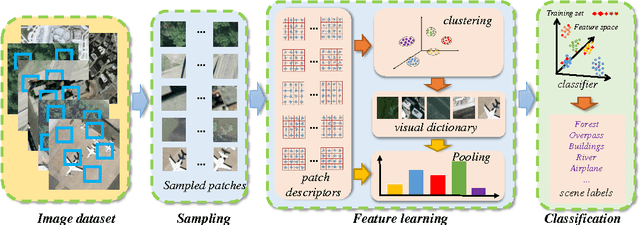
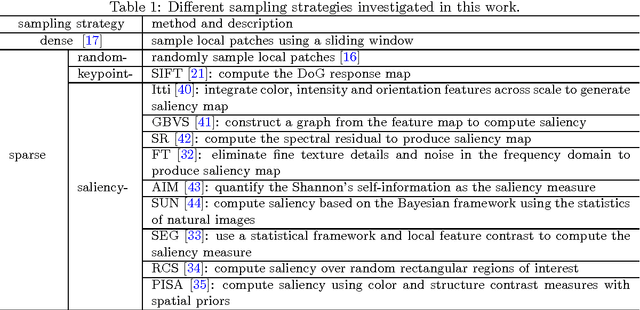

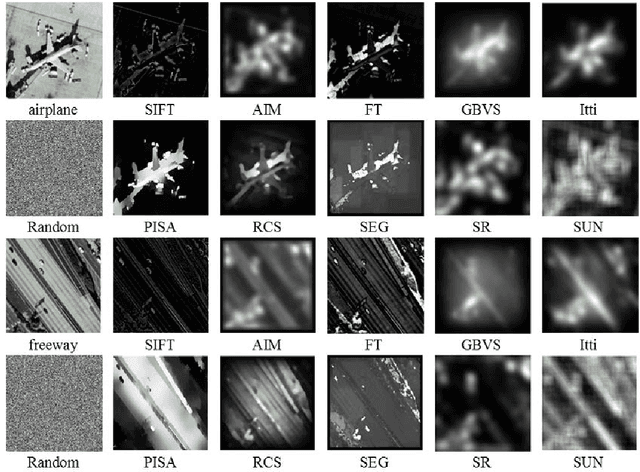
Scene classification is a key problem in the interpretation of high-resolution remote sensing imagery. Many state-of-the-art methods, e.g. bag-of-visual-words model and its variants, the topic models as well as deep learning-based approaches, share similar procedures: patch sampling, feature description/learning and classification. Patch sampling is the first and a key procedure which has a great influence on the results. In the literature, many different sampling strategies have been used, {e.g. dense sampling, random sampling, keypoint-based sampling and saliency-based sampling, etc. However, it is still not clear which sampling strategy is suitable for the scene classification of high-resolution remote sensing images. In this paper, we comparatively study the effects of different sampling strategies under the scenario of scene classification of high-resolution remote sensing images. We divide the existing sampling methods into two types: dense sampling and sparse sampling, the later of which includes random sampling, keypoint-based sampling and various saliency-based sampling proposed recently. In order to compare their performances, we rely on a standard bag-of-visual-words model to construct our testing scheme, owing to their simplicity, robustness and efficiency. The experimental results on two commonly used datasets show that dense sampling has the best performance among all the strategies but with high spatial and computational complexity, random sampling gives better or comparable results than other sparse sampling methods, like the sophisticated multi-scale key-point operators and the saliency-based methods which are intensively studied and commonly used recently.