 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMGCN: Multimodal Fusion via Deep Graph Convolution Network for Emotion Recognition in Conversation
Paper and Code
Jul 14, 2021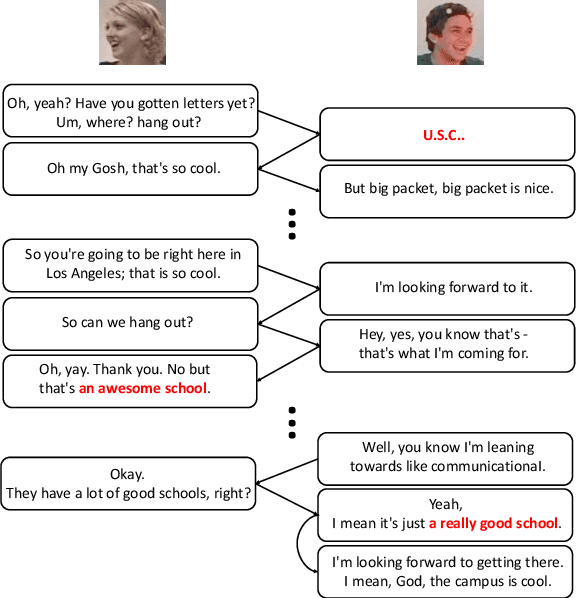
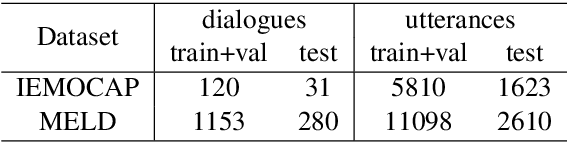
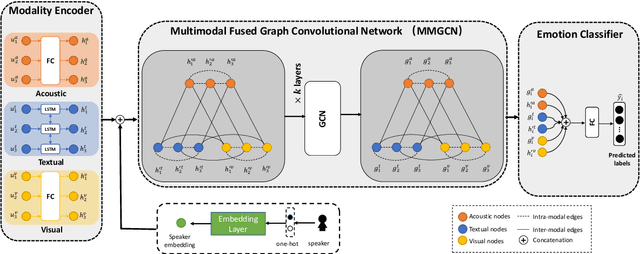
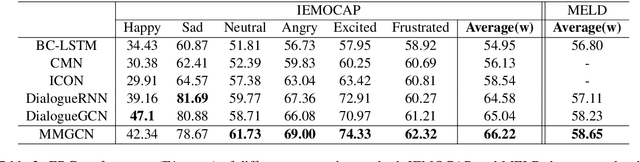
Emotion recognition in conversation (ERC) is a crucial component in affective dialogue systems, which helps the system understand users' emotions and generate empathetic responses. However, most works focus on modeling speaker and contextual information primarily on the textual modality or simply leveraging multimodal information through feature concatenation. In order to explore a more effective way of utilizing both multimodal and long-distance contextual information, we propose a new model based on multimodal fused graph convolutional network, MMGCN, in this work. MMGCN can not only make use of multimodal dependencies effectively, but also leverage speaker information to model inter-speaker and intra-speaker dependency. We evaluate our proposed model on two public benchmark datasets, IEMOCAP and MELD, and the results prove the effectiveness of MMGCN, which outperforms other SOTA methods by a significant margin under the multimodal conversation setting.