 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-based Point Cloud Registration for 6D Object Pose Estimation in the Real World
Mar 29, 2022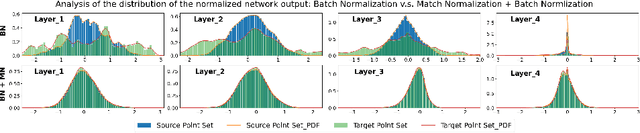
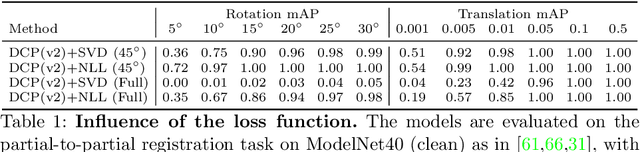
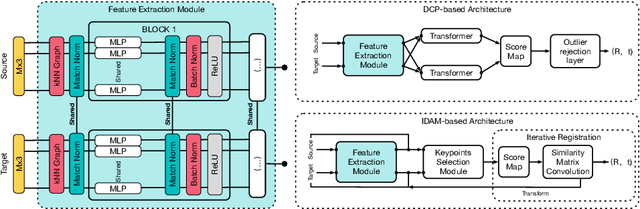
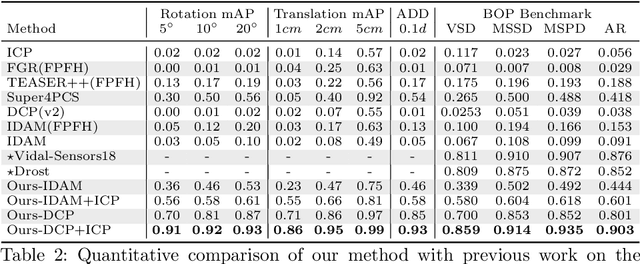
In this work, we tackle the task of estimating the 6D pose of an object from point cloud data. While recent learning-based approaches to addressing this task have shown great success on synthetic datasets, we have observed them to fail in the presence of real-world data. We thus analyze the causes of these failures, which we trace back to the difference between the feature distributions of the source and target point clouds, and the sensitivity of the widely-used SVD-based loss function to the range of rotation between the two point clouds. We address the first challenge by introducing a new normalization strategy, Match Normalization, and the second via the use of a loss function based on the negative log likelihood of point correspondences. Our two contributions are general and can be applied to many existing learning-based 3D object registration frameworks, which we illustrate by implementing them in two of them, DCP and IDAM. Our experiments on the real-scene TUD-L, LINEMOD and Occluded-LINEMOD datasets evidence the benefits of our strategies. They allow for the first time learning-based 3D object registration methods to achieve meaningful results on real-world data. We therefore expect them to be key to the future development of point cloud registration methods.
What Stops Learning-based 3D Registration from Working in the Real World?
Nov 19, 2021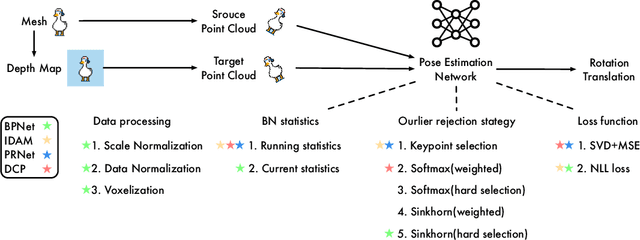



Much progress has been made on the task of learning-based 3D point cloud registration, with existing methods yielding outstanding results on standard benchmarks, such as ModelNet40, even in the partial-to-partial matching scenario. Unfortunately, these methods still struggle in the presence of real data. In this work, we identify the sources of these failures, analyze the reasons behind them, and propose solutions to tackle them. We summarise our findings into a set of guidelines and demonstrate their effectiveness by applying them to different baseline methods, DCP and IDAM. In short, our guidelines improve both their training convergence and testing accuracy. Ultimately, this translates to a best-practice 3D registration network (BPNet), constituting the first learning-based method able to handle previously-unseen objects in real-world data. Despite being trained only on synthetic data, our model generalizes to real data without any fine-tuning, reaching an accuracy of up to 67% on point clouds of unseen objects obtained with a commercial sensor.