 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Shape Completion via Involution and Implicit Correspondences
Sep 24, 2024



3D shape completion is traditionally solved using supervised training or by distribution learning on complete shape examples. Recently self-supervised learning approaches that do not require any complete 3D shape examples have gained more interests. In this paper, we propose a non-adversarial self-supervised approach for the shape completion task. Our first finding is that completion problems can be formulated as an involutory function trivially, which implies a special constraint on the completion function G, such that G(G(X)) = X. Our second constraint on self-supervised shape completion relies on the fact that shape completion becomes easier to solve with correspondences and similarly, completion can simplify the correspondences problem. We formulate a consistency measure in the canonical space in order to supervise the completion function. We efficiently optimize the completion and correspondence modules using "freeze and alternate" strategy. The overall approach performs well for rigid shapes in a category as well as dynamic non-rigid shapes. We ablate our design choices and compare our solution against state-of-the-art methods, showing remarkable accuracy approaching supervised accuracy in some cases.
3D Compression Using Neural Fields
Nov 21, 2023Neural Fields (NFs) have gained momentum as a tool for compressing various data modalities - e.g. images and videos. This work leverages previous advances and proposes a novel NF-based compression algorithm for 3D data. We derive two versions of our approach - one tailored to watertight shapes based on Signed Distance Fields (SDFs) and, more generally, one for arbitrary non-watertight shapes using Unsigned Distance Fields (UDFs). We demonstrate that our method excels at geometry compression on 3D point clouds as well as meshes. Moreover, we show that, due to the NF formulation, it is straightforward to extend our compression algorithm to compress both geometry and attribute (e.g. color) of 3D data.
ManiFlow: Implicitly Representing Manifolds with Normalizing Flows
Aug 18, 2022


Normalizing Flows (NFs) are flexible explicit generative models that have been shown to accurately model complex real-world data distributions. However, their invertibility constraint imposes limitations on data distributions that reside on lower dimensional manifolds embedded in higher dimensional space. Practically, this shortcoming is often bypassed by adding noise to the data which impacts the quality of the generated samples. In contrast to prior work, we approach this problem by generating samples from the original data distribution given full knowledge about the perturbed distribution and the noise model. To this end, we establish that NFs trained on perturbed data implicitly represent the manifold in regions of maximum likelihood. Then, we propose an optimization objective that recovers the most likely point on the manifold given a sample from the perturbed distribution. Finally, we focus on 3D point clouds for which we utilize the explicit nature of NFs, i.e. surface normals extracted from the gradient of the log-likelihood and the log-likelihood itself, to apply Poisson surface reconstruction to refine generated point sets.
SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation
Jun 16, 2022



Adapting to a continuously evolving environment is a safety-critical challenge inevitably faced by all autonomous driving systems. Existing image and video driving datasets, however, fall short of capturing the mutable nature of the real world. In this paper, we introduce the largest multi-task synthetic dataset for autonomous driving, SHIFT. It presents discrete and continuous shifts in cloudiness, rain and fog intensity, time of day, and vehicle and pedestrian density. Featuring a comprehensive sensor suite and annotations for several mainstream perception tasks, SHIFT allows investigating the degradation of a perception system performance at increasing levels of domain shift, fostering the development of continuous adaptation strategies to mitigate this problem and assess model robustness and generality. Our dataset and benchmark toolkit are publicly available at www.vis.xyz/shift.
Implicit Neural Representations for Image Compression
Dec 08, 2021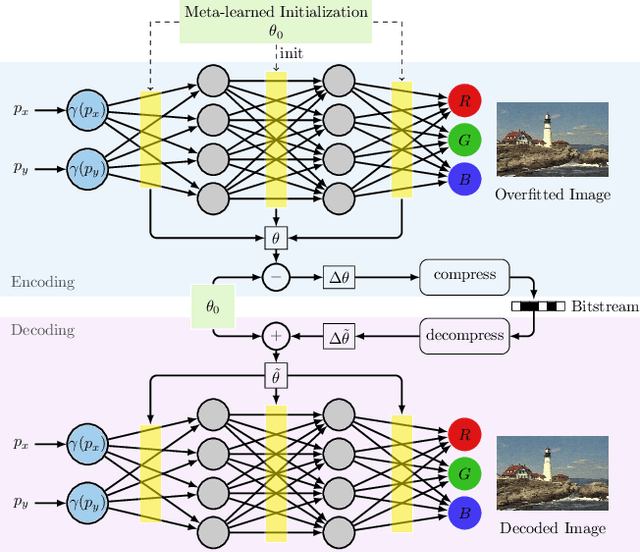
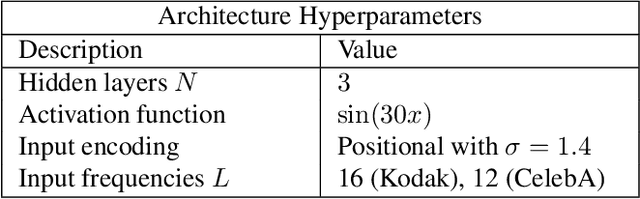

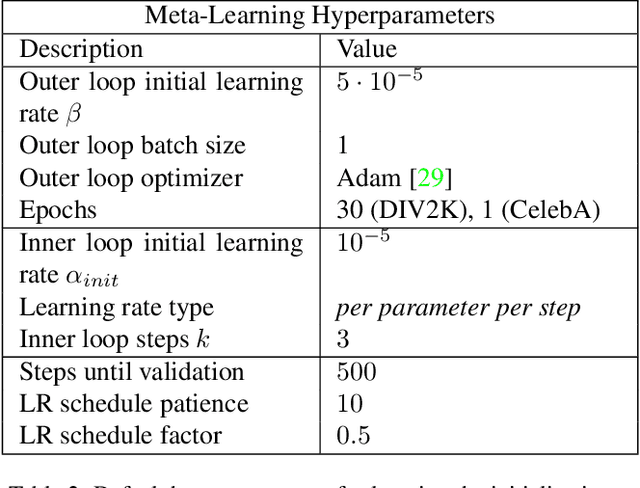
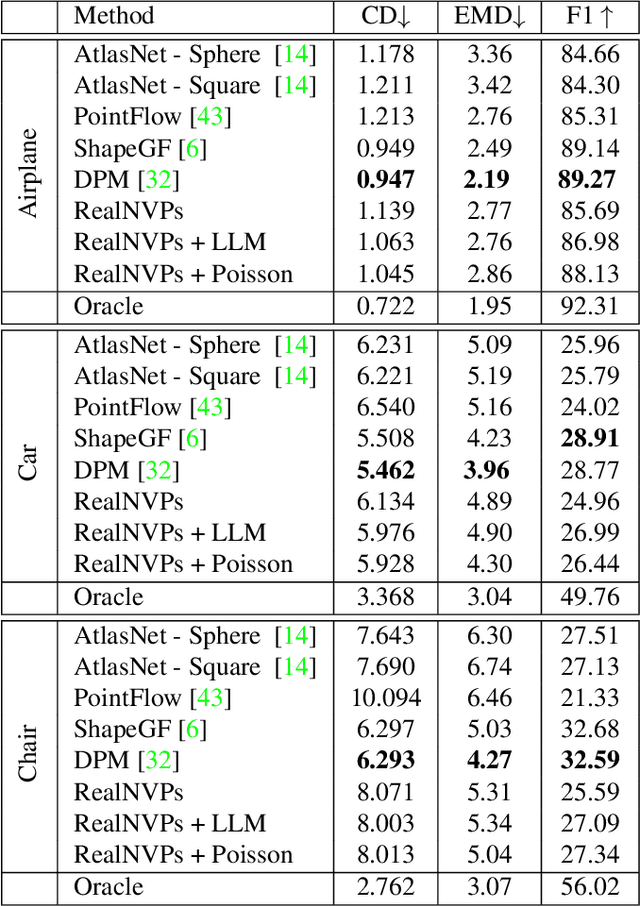
Recently Implicit Neural Representations (INRs) gained attention as a novel and effective representation for various data types. Thus far, prior work mostly focused on optimizing their reconstruction performance. This work investigates INRs from a novel perspective, i.e., as a tool for image compression. To this end, we propose the first comprehensive compression pipeline based on INRs including quantization, quantization-aware retraining and entropy coding. Encoding with INRs, i.e. overfitting to a data sample, is typically orders of magnitude slower. To mitigate this drawback, we leverage meta-learned initializations based on MAML to reach the encoding in fewer gradient updates which also generally improves rate-distortion performance of INRs. We find that our approach to source compression with INRs vastly outperforms similar prior work, is competitive with common compression algorithms designed specifically for images and closes the gap to state-of-the-art learned approaches based on Rate-Distortion Autoencoders. Moreover, we provide an extensive ablation study on the importance of individual components of our method which we hope facilitates future research on this novel approach to image compression.
On the Practicality of Deterministic Epistemic Uncertainty
Jul 13, 2021



A set of novel approaches for estimating epistemic uncertainty in deep neural networks with a single forward pass has recently emerged as a valid alternative to Bayesian Neural Networks. On the premise of informative representations, these deterministic uncertainty methods (DUMs) achieve strong performance on detecting out-of-distribution (OOD) data while adding negligible computational costs at inference time. However, it remains unclear whether DUMs are well calibrated and can seamlessly scale to real-world applications - both prerequisites for their practical deployment. To this end, we first provide a taxonomy of DUMs, evaluate their calibration under continuous distributional shifts and their performance on OOD detection for image classification tasks. Then, we extend the most promising approaches to semantic segmentation. We find that, while DUMs scale to realistic vision tasks and perform well on OOD detection, the practicality of current methods is undermined by poor calibration under realistic distributional shifts.
Go with the Flows: Mixtures of Normalizing Flows for Point Cloud Generation and Reconstruction
Jun 18, 2021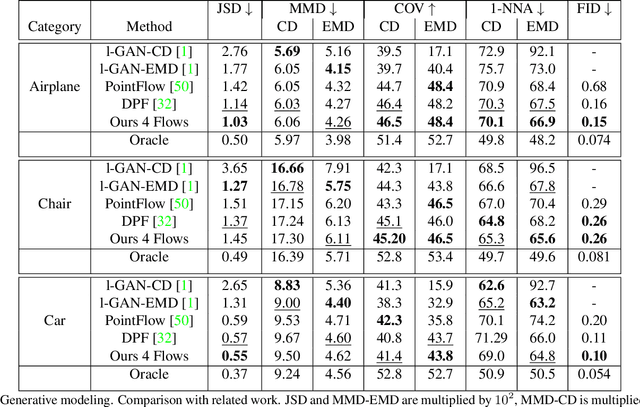
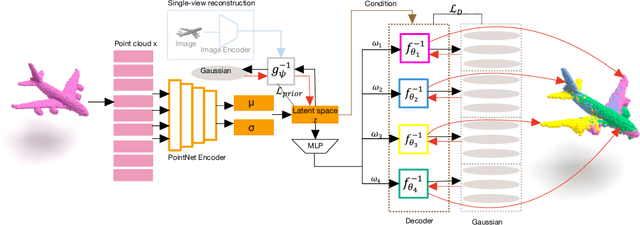
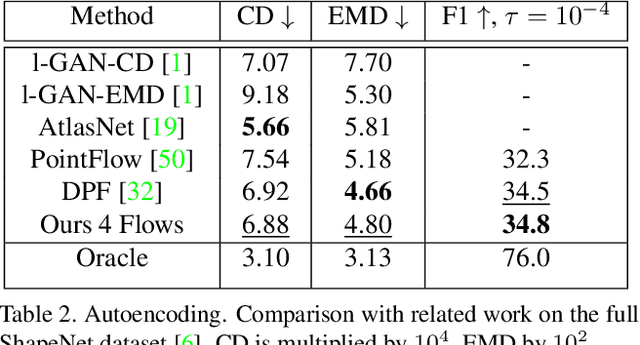
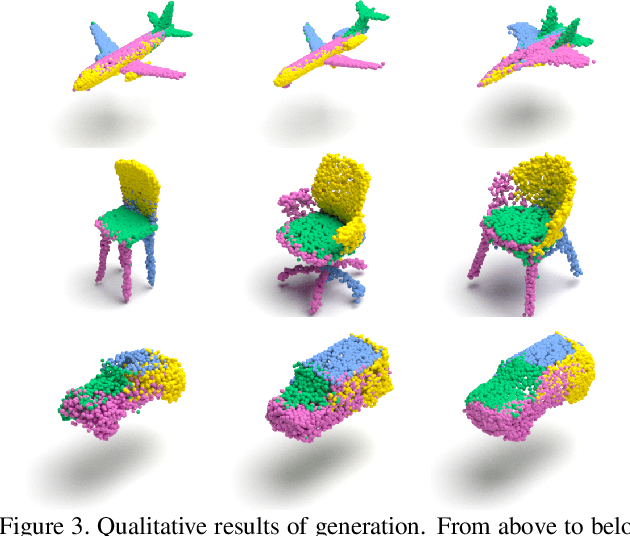
Recently normalizing flows (NFs) have demonstrated state-of-the-art performance on modeling 3D point clouds while allowing sampling with arbitrary resolution at inference time. However, these flow-based models still require long training times and large models for representing complicated geometries. This work enhances their representational power by applying mixtures of NFs to point clouds. We show that in this more general framework each component learns to specialize in a particular subregion of an object in a completely unsupervised fashion. By instantiating each mixture component with a comparatively small NF we generate point clouds with improved details compared to single-flow-based models while using fewer parameters and considerably reducing the inference runtime. We further demonstrate that by adding data augmentation, individual mixture components can learn to specialize in a semantically meaningful manner. We evaluate mixtures of NFs on generation, autoencoding and single-view reconstruction based on the ShapeNet dataset.
Variational Transformer Networks for Layout Generation
Apr 06, 2021
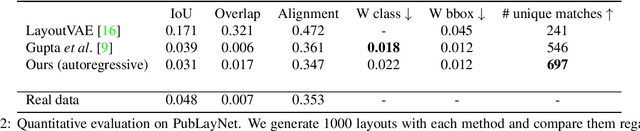


Generative models able to synthesize layouts of different kinds (e.g. documents, user interfaces or furniture arrangements) are a useful tool to aid design processes and as a first step in the generation of synthetic data, among other tasks. We exploit the properties of self-attention layers to capture high level relationships between elements in a layout, and use these as the building blocks of the well-known Variational Autoencoder (VAE) formulation. Our proposed Variational Transformer Network (VTN) is capable of learning margins, alignments and other global design rules without explicit supervision. Layouts sampled from our model have a high degree of resemblance to the training data, while demonstrating appealing diversity. In an extensive evaluation on publicly available benchmarks for different layout types VTNs achieve state-of-the-art diversity and perceptual quality. Additionally, we show the capabilities of this method as part of a document layout detection pipeline.
Quantifying Aleatoric and Epistemic Uncertainty Using Density Estimation in Latent Space
Dec 05, 2020



The distribution of a neural network's latent representations has been successfully used to detect Out-of-Distribution (OOD) data. Since OOD detection denotes a popular benchmark for epistemic uncertainty estimates, this raises the question of a deeper correlation. This work investigates whether the distribution of latent representations indeed contains information about the uncertainty associated with the predictions of a neural network. Prior work identifies epistemic uncertainty with the surprise, thus the negative log-likelihood, of observing a particular latent representation, which we verify empirically. Moreover, we demonstrate that the output-conditional distribution of hidden representations allows quantifying aleatoric uncertainty via the entropy of the predictive distribution. We analyze epistemic and aleatoric uncertainty inferred from the representations of different layers and conclude with the exciting finding that the hidden repesentations of a deterministic neural network indeed contain information about its uncertainty. We verify our findings on both classification and regression models.
Sampling-free Epistemic Uncertainty Estimation Using Approximated Variance Propagation
Aug 21, 2019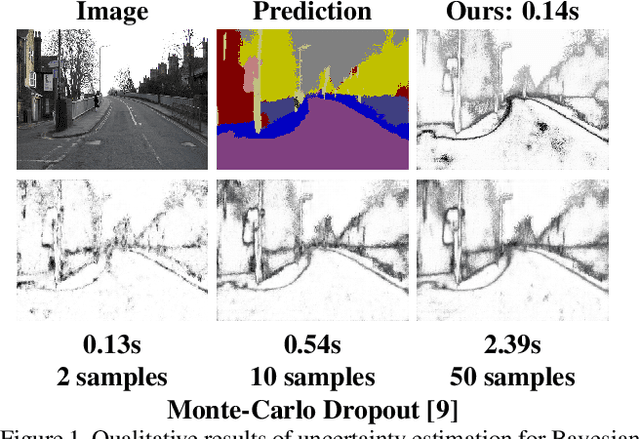
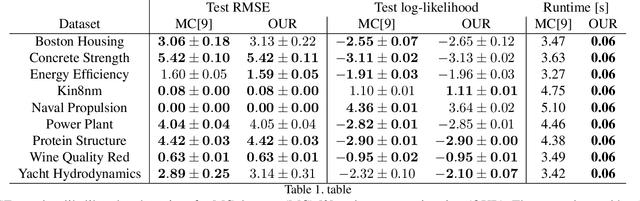
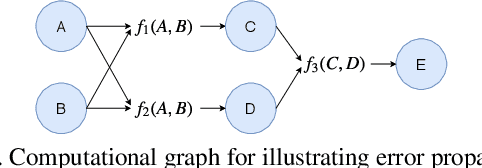
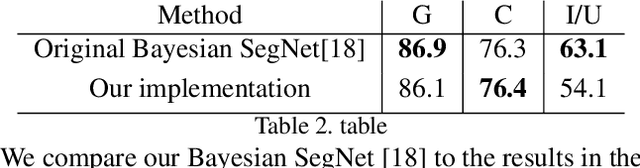
We present a sampling-free approach for computing the epistemic uncertainty of a neural network. Epistemic uncertainty is an important quantity for the deployment of deep neural networks in safety-critical applications, since it represents how much one can trust predictions on new data. Recently promising works were proposed using noise injection combined with Monte-Carlo sampling at inference time to estimate this quantity (e.g. Monte-Carlo dropout). Our main contribution is an approximation of the epistemic uncertainty estimated by these methods that does not require sampling, thus notably reducing the computational overhead. We apply our approach to large-scale visual tasks (i.e., semantic segmentation and depth regression) to demonstrate the advantages of our method compared to sampling-based approaches in terms of quality of the uncertainty estimates as well as of computational overhead.