 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeseqme: a Python library for evaluating biological sequence design
Nov 06, 2025Recent advances in computational methods for designing biological sequences have sparked the development of metrics to evaluate these methods performance in terms of the fidelity of the designed sequences to a target distribution and their attainment of desired properties. However, a single software library implementing these metrics was lacking. In this work we introduce seqme, a modular and highly extendable open-source Python library, containing model-agnostic metrics for evaluating computational methods for biological sequence design. seqme considers three groups of metrics: sequence-based, embedding-based, and property-based, and is applicable to a wide range of biological sequences: small molecules, DNA, ncRNA, mRNA, peptides and proteins. The library offers a number of embedding and property models for biological sequences, as well as diagnostics and visualization functions to inspect the results. seqme can be used to evaluate both one-shot and iterative computational design methods.
Unified Molecule Generation and Property Prediction
Apr 23, 2025Modeling the joint distribution of the data samples and their properties allows to construct a single model for both data generation and property prediction, with synergistic capabilities reaching beyond purely generative or predictive models. However, training joint models presents daunting architectural and optimization challenges. Here, we propose Hyformer, a transformer-based joint model that successfully blends the generative and predictive functionalities, using an alternating attention mask together with a unified pre-training scheme. We show that Hyformer rivals other joint models, as well as state-of-the-art molecule generation and property prediction models. Additionally, we show the benefits of joint modeling in downstream tasks of molecular representation learning, hit identification and antimicrobial peptide design.
Token Recycling for Efficient Sequential Inference with Vision Transformers
Nov 26, 2023
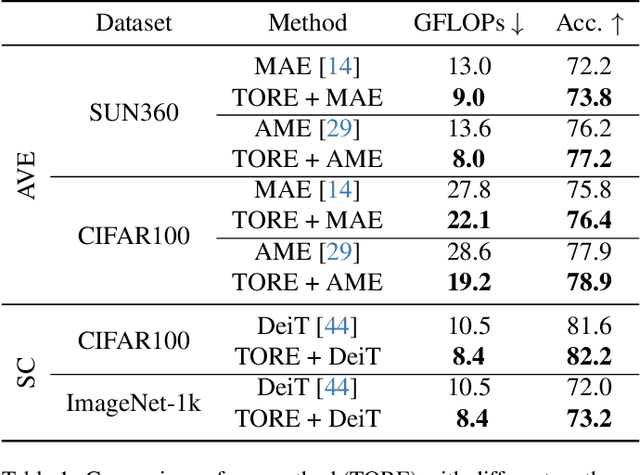
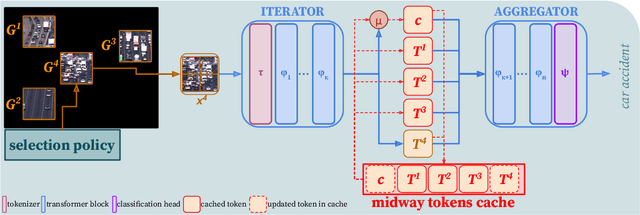
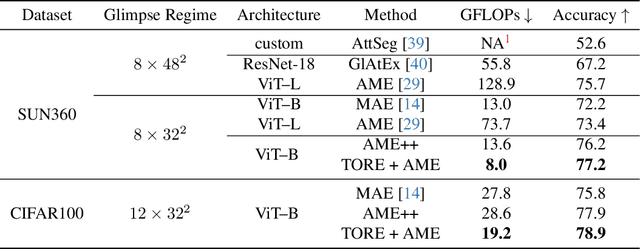
Vision Transformers (ViTs) overpass Convolutional Neural Networks in processing incomplete inputs because they do not require the imputation of missing values. Therefore, ViTs are well suited for sequential decision-making, e.g. in the Active Visual Exploration problem. However, they are computationally inefficient because they perform a full forward pass each time a piece of new sequential information arrives. To reduce this computational inefficiency, we introduce the TOken REcycling (TORE) modification for the ViT inference, which can be used with any architecture. TORE divides ViT into two parts, iterator and aggregator. An iterator processes sequential information separately into midway tokens, which are cached. The aggregator processes midway tokens jointly to obtain the prediction. This way, we can reuse the results of computations made by iterator. Except for efficient sequential inference, we propose a complementary training policy, which significantly reduces the computational burden associated with sequential decision-making while achieving state-of-the-art accuracy.
Beyond Grids: Exploring Elastic Input Sampling for Vision Transformers
Sep 23, 2023Vision transformers have excelled in various computer vision tasks but mostly rely on rigid input sampling using a fixed-size grid of patches. This limits their applicability in real-world problems, such as in the field of robotics and UAVs, where one can utilize higher input elasticity to boost model performance and efficiency. Our paper addresses this limitation by formalizing the concept of input elasticity for vision transformers and introducing an evaluation protocol, including dedicated metrics for measuring input elasticity. Moreover, we propose modifications to the transformer architecture and training regime, which increase its elasticity. Through extensive experimentation, we spotlight opportunities and challenges associated with input sampling strategies.
HashCC: Lightweight Method to Improve the Quality of the Camera-less NeRF Scene Generation
May 07, 2023



Neural Radiance Fields has become a prominent method of scene generation via view synthesis. A critical requirement for the original algorithm to learn meaningful scene representation is camera pose information for each image in a data set. Current approaches try to circumnavigate this assumption with moderate success, by learning approximate camera positions alongside learning neural representations of a scene. This requires complicated camera models, causing a long and complicated training process, or results in a lack of texture and sharp details in rendered scenes. In this work we introduce Hash Color Correction (HashCC) -- a lightweight method for improving Neural Radiance Fields rendered image quality, applicable also in situations where camera positions for a given set of images are unknown.