 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStitch: Training-Free Position Control in Multimodal Diffusion Transformers
Sep 30, 2025Text-to-Image (T2I) generation models have advanced rapidly in recent years, but accurately capturing spatial relationships like "above" or "to the right of" poses a persistent challenge. Earlier methods improved spatial relationship following with external position control. However, as architectures evolved to enhance image quality, these techniques became incompatible with modern models. We propose Stitch, a training-free method for incorporating external position control into Multi-Modal Diffusion Transformers (MMDiT) via automatically-generated bounding boxes. Stitch produces images that are both spatially accurate and visually appealing by generating individual objects within designated bounding boxes and seamlessly stitching them together. We find that targeted attention heads capture the information necessary to isolate and cut out individual objects mid-generation, without needing to fully complete the image. We evaluate Stitch on PosEval, our benchmark for position-based T2I generation. Featuring five new tasks that extend the concept of Position beyond the basic GenEval task, PosEval demonstrates that even top models still have significant room for improvement in position-based generation. Tested on Qwen-Image, FLUX, and SD3.5, Stitch consistently enhances base models, even improving FLUX by 218% on GenEval's Position task and by 206% on PosEval. Stitch achieves state-of-the-art results with Qwen-Image on PosEval, improving over previous models by 54%, all accomplished while integrating position control into leading models training-free. Code is available at https://github.com/ExplainableML/Stitch.
Sparse Autoencoders Learn Monosemantic Features in Vision-Language Models
Apr 03, 2025Sparse Autoencoders (SAEs) have recently been shown to enhance interpretability and steerability in Large Language Models (LLMs). In this work, we extend the application of SAEs to Vision-Language Models (VLMs), such as CLIP, and introduce a comprehensive framework for evaluating monosemanticity in vision representations. Our experimental results reveal that SAEs trained on VLMs significantly enhance the monosemanticity of individual neurons while also exhibiting hierarchical representations that align well with expert-defined structures (e.g., iNaturalist taxonomy). Most notably, we demonstrate that applying SAEs to intervene on a CLIP vision encoder, directly steer output from multimodal LLMs (e.g., LLaVA) without any modifications to the underlying model. These findings emphasize the practicality and efficacy of SAEs as an unsupervised approach for enhancing both the interpretability and control of VLMs.
LucidPPN: Unambiguous Prototypical Parts Network for User-centric Interpretable Computer Vision
May 23, 2024



Prototypical parts networks combine the power of deep learning with the explainability of case-based reasoning to make accurate, interpretable decisions. They follow the this looks like that reasoning, representing each prototypical part with patches from training images. However, a single image patch comprises multiple visual features, such as color, shape, and texture, making it difficult for users to identify which feature is important to the model. To reduce this ambiguity, we introduce the Lucid Prototypical Parts Network (LucidPPN), a novel prototypical parts network that separates color prototypes from other visual features. Our method employs two reasoning branches: one for non-color visual features, processing grayscale images, and another focusing solely on color information. This separation allows us to clarify whether the model's decisions are based on color, shape, or texture. Additionally, LucidPPN identifies prototypical parts corresponding to semantic parts of classified objects, making comparisons between data classes more intuitive, e.g., when two bird species might differ primarily in belly color. Our experiments demonstrate that the two branches are complementary and together achieve results comparable to baseline methods. More importantly, LucidPPN generates less ambiguous prototypical parts, enhancing user understanding.
Token Recycling for Efficient Sequential Inference with Vision Transformers
Nov 26, 2023
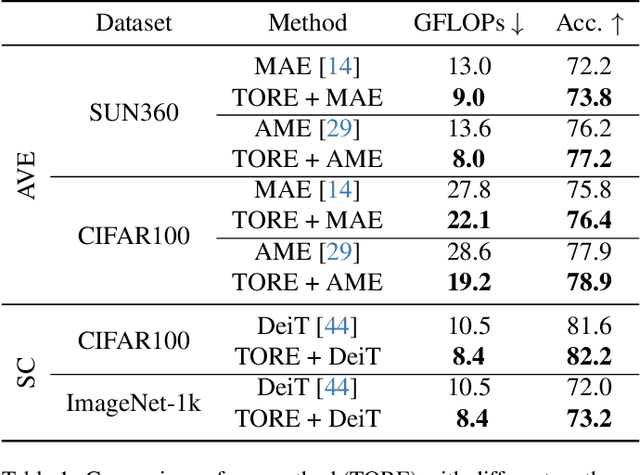
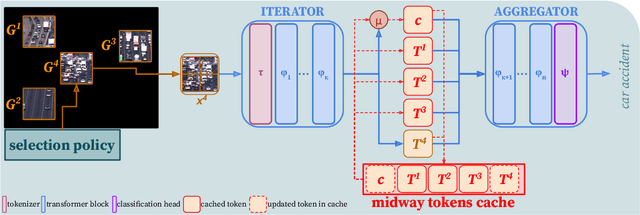
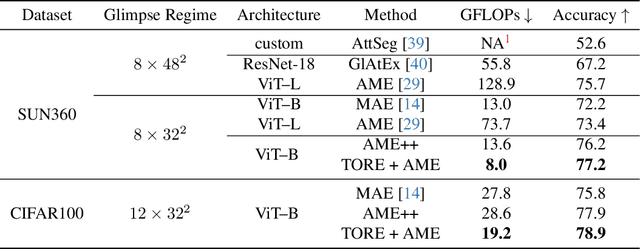
Vision Transformers (ViTs) overpass Convolutional Neural Networks in processing incomplete inputs because they do not require the imputation of missing values. Therefore, ViTs are well suited for sequential decision-making, e.g. in the Active Visual Exploration problem. However, they are computationally inefficient because they perform a full forward pass each time a piece of new sequential information arrives. To reduce this computational inefficiency, we introduce the TOken REcycling (TORE) modification for the ViT inference, which can be used with any architecture. TORE divides ViT into two parts, iterator and aggregator. An iterator processes sequential information separately into midway tokens, which are cached. The aggregator processes midway tokens jointly to obtain the prediction. This way, we can reuse the results of computations made by iterator. Except for efficient sequential inference, we propose a complementary training policy, which significantly reduces the computational burden associated with sequential decision-making while achieving state-of-the-art accuracy.