 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeDSLIP: Medical Dual-Stream Language-Image Pre-training for Fine-grained Alignment
Mar 15, 2024Vision-language pre-training (VLP) models have shown significant advancements in the medical domain. Yet, most VLP models align raw reports to images at a very coarse level, without modeling fine-grained relationships between anatomical and pathological concepts outlined in reports and the corresponding semantic counterparts in images. To address this problem, we propose a Medical Dual-Stream Language-Image Pre-training (MeDSLIP) framework. Specifically, MeDSLIP establishes vision-language fine-grained alignments via disentangling visual and textual representations into anatomy-relevant and pathology-relevant streams. Moreover, a novel vision-language Prototypical Contr-astive Learning (ProtoCL) method is adopted in MeDSLIP to enhance the alignment within the anatomical and pathological streams. MeDSLIP further employs cross-stream Intra-image Contrastive Learning (ICL) to ensure the consistent coexistence of paired anatomical and pathological concepts within the same image. Such a cross-stream regularization encourages the model to exploit the synchrony between two streams for a more comprehensive representation learning. MeDSLIP is evaluated under zero-shot and supervised fine-tuning settings on three public datasets: NIH CXR14, RSNA Pneumonia, and SIIM-ACR Pneumothorax. Under these settings, MeDSLIP outperforms six leading CNN-based models on classification, grounding, and segmentation tasks.
Noninvasive Estimation of Mean Pulmonary Artery Pressure Using MRI, Computer Models, and Machine Learning
Dec 21, 2023Pulmonary Hypertension (PH) is a severe disease characterized by an elevated pulmonary artery pressure. The gold standard for PH diagnosis is measurement of mean Pulmonary Artery Pressure (mPAP) during an invasive Right Heart Catheterization. In this paper, we investigate noninvasive approach to PH detection utilizing Magnetic Resonance Imaging, Computer Models and Machine Learning. We show using the ablation study, that physics-informed feature engineering based on models of blood circulation increases the performance of Gradient Boosting Decision Trees-based algorithms for classification of PH and regression of values of mPAP. We compare results of regression (with thresholding of estimated mPAP) and classification and demonstrate that metrics achieved in both experiments are comparable. The predicted mPAP values are more informative to the physicians than the probability of PH returned by classification models. They provide the intuitive explanation of the outcome of the machine learning model (clinicians are accustomed to the mPAP metric, contrary to the PH probability).
Utilizing Transfer Learning and a Customized Loss Function for Optic Disc Segmentation from Retinal Images
Oct 01, 2020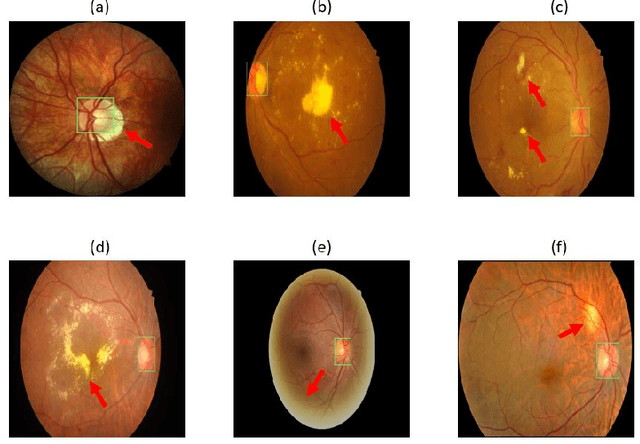
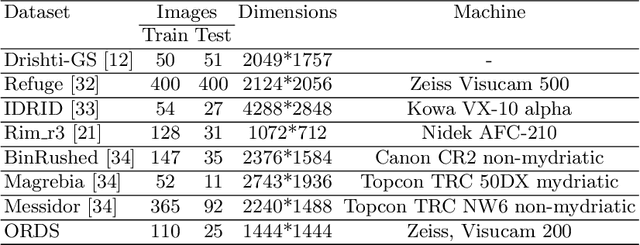
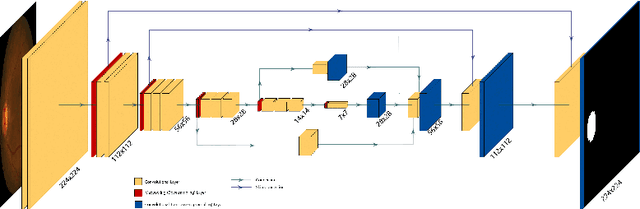
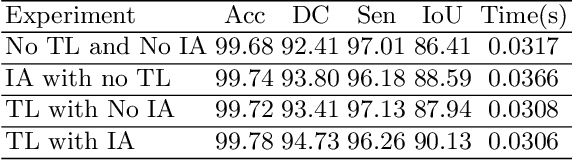
Accurate segmentation of the optic disc from a retinal image is vital to extracting retinal features that may be highly correlated with retinal conditions such as glaucoma. In this paper, we propose a deep-learning based approach capable of segmenting the optic disc given a high-precision retinal fundus image. Our approach utilizes a UNET-based model with a VGG16 encoder trained on the ImageNet dataset. This study can be distinguished from other studies in the customization made for the VGG16 model, the diversity of the datasets adopted, the duration of disc segmentation, the loss function utilized, and the number of parameters required to train our model. Our approach was tested on seven publicly available datasets augmented by a dataset from a private clinic that was annotated by two Doctors of Optometry through a web portal built for this purpose. We achieved an accuracy of 99.78\% and a Dice coefficient of 94.73\% for a disc segmentation from a retinal image in 0.03 seconds. The results obtained from comprehensive experiments demonstrate the robustness of our approach to disc segmentation of retinal images obtained from different sources.