 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRAGyan -- Connecting the Dots in Tweets
Jul 18, 2024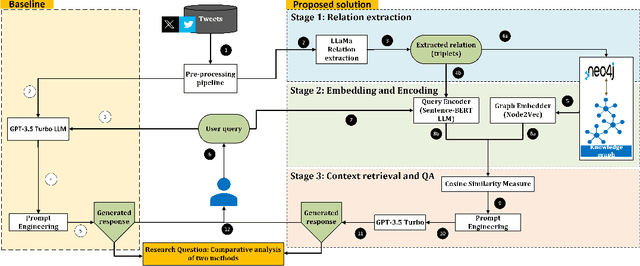



As social media platforms grow, understanding the underlying reasons behind events and statements becomes crucial for businesses, policymakers, and researchers. This research explores the integration of Knowledge Graphs (KGs) with Large Language Models (LLMs) to perform causal analysis of tweets dataset. The LLM aided analysis techniques often lack depth in uncovering the causes driving observed effects. By leveraging KGs and LLMs, which encode rich semantic relationships and temporal information, this study aims to uncover the complex interplay of factors influencing causal dynamics and compare the results obtained using GPT-3.5 Turbo. We employ a Retrieval-Augmented Generation (RAG) model, utilizing a KG stored in a Neo4j (a.k.a PRAGyan) data format, to retrieve relevant context for causal reasoning. Our approach demonstrates that the KG-enhanced LLM RAG can provide improved results when compared to the baseline LLM (GPT-3.5 Turbo) model as the source corpus increases in size. Our qualitative analysis highlights the advantages of combining KGs with LLMs for improved interpretability and actionable insights, facilitating informed decision-making across various domains. Whereas, quantitative analysis using metrics such as BLEU and cosine similarity show that our approach outperforms the baseline by 10\%.
Transfer Learning Through Weighted Loss Function and Group Normalization for Vessel Segmentation from Retinal Images
Dec 16, 2020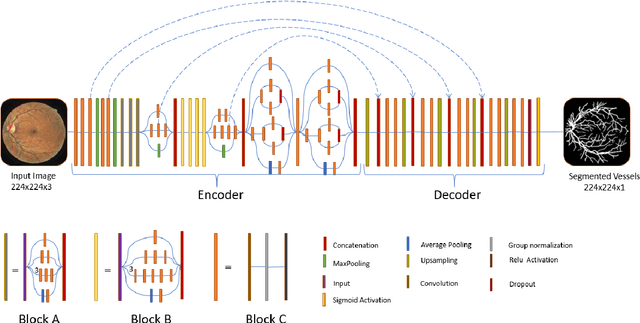
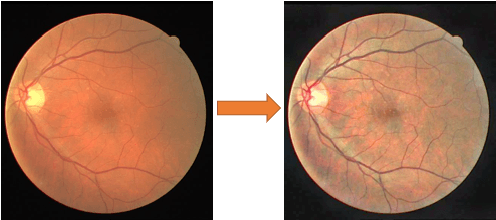
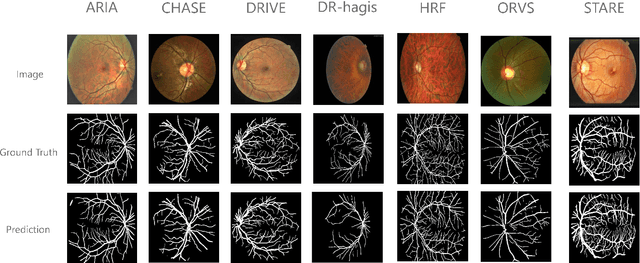

The vascular structure of blood vessels is important in diagnosing retinal conditions such as glaucoma and diabetic retinopathy. Accurate segmentation of these vessels can help in detecting retinal objects such as the optic disc and optic cup and hence determine if there are damages to these areas. Moreover, the structure of the vessels can help in diagnosing glaucoma. The rapid development of digital imaging and computer-vision techniques has increased the potential for developing approaches for segmenting retinal vessels. In this paper, we propose an approach for segmenting retinal vessels that uses deep learning along with transfer learning. We adapted the U-Net structure to use a customized InceptionV3 as the encoder and used multiple skip connections to form the decoder. Moreover, we used a weighted loss function to handle the issue of class imbalance in retinal images. Furthermore, we contributed a new dataset to this field. We tested our approach on six publicly available datasets and a newly created dataset. We achieved an average accuracy of 95.60% and a Dice coefficient of 80.98%. The results obtained from comprehensive experiments demonstrate the robustness of our approach to the segmentation of blood vessels in retinal images obtained from different sources. Our approach results in greater segmentation accuracy than other approaches.
Utilizing Transfer Learning and a Customized Loss Function for Optic Disc Segmentation from Retinal Images
Oct 01, 2020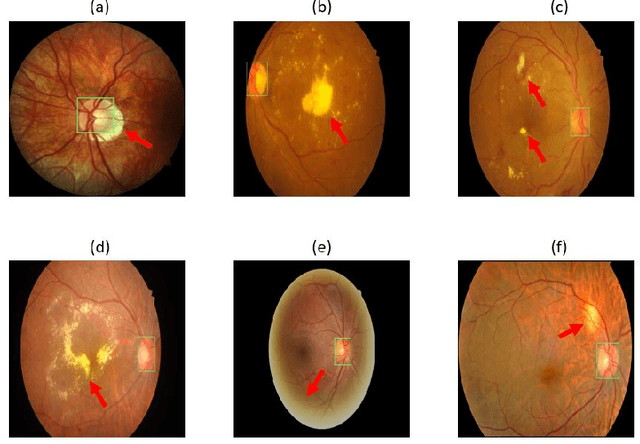
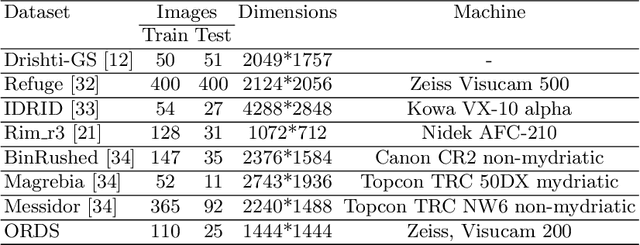
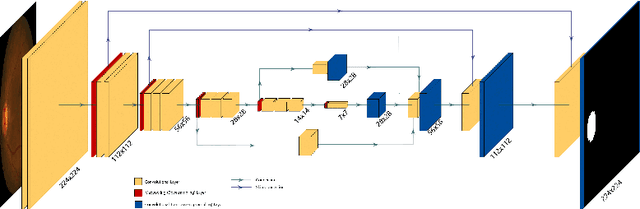
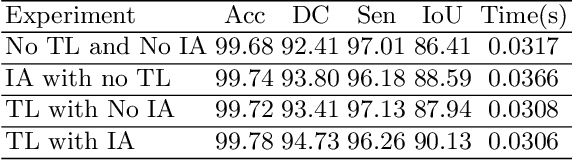
Accurate segmentation of the optic disc from a retinal image is vital to extracting retinal features that may be highly correlated with retinal conditions such as glaucoma. In this paper, we propose a deep-learning based approach capable of segmenting the optic disc given a high-precision retinal fundus image. Our approach utilizes a UNET-based model with a VGG16 encoder trained on the ImageNet dataset. This study can be distinguished from other studies in the customization made for the VGG16 model, the diversity of the datasets adopted, the duration of disc segmentation, the loss function utilized, and the number of parameters required to train our model. Our approach was tested on seven publicly available datasets augmented by a dataset from a private clinic that was annotated by two Doctors of Optometry through a web portal built for this purpose. We achieved an accuracy of 99.78\% and a Dice coefficient of 94.73\% for a disc segmentation from a retinal image in 0.03 seconds. The results obtained from comprehensive experiments demonstrate the robustness of our approach to disc segmentation of retinal images obtained from different sources.