 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Enhance Bug Report Quality Using LLMs?: An Empirical Study of LLM-Based Bug Report Generation
Apr 26, 2025Bug reports contain the information developers need to triage and fix software bugs. However, unclear, incomplete, or ambiguous information may lead to delays and excessive manual effort spent on bug triage and resolution. In this paper, we explore whether Instruction fine-tuned Large Language Models (LLMs) can automatically transform casual, unstructured bug reports into high-quality, structured bug reports adhering to a standard template. We evaluate three open-source instruction-tuned LLMs (\emph{Qwen 2.5, Mistral, and Llama 3.2}) against ChatGPT-4o, measuring performance on established metrics such as CTQRS, ROUGE, METEOR, and SBERT. Our experiments show that fine-tuned Qwen 2.5 achieves a CTQRS score of \textbf{77%}, outperforming both fine-tuned Mistral (\textbf{71%}), Llama 3.2 (\textbf{63%}) and ChatGPT in 3-shot learning (\textbf{75%}). Further analysis reveals that Llama 3.2 shows higher accuracy of detecting missing fields particularly Expected Behavior and Actual Behavior, while Qwen 2.5 demonstrates superior performance in capturing Steps-to-Reproduce, with an F1 score of 76%. Additional testing of the models on other popular projects (e.g., Eclipse, GCC) demonstrates that our approach generalizes well, achieving up to \textbf{70%} CTQRS in unseen projects' bug reports. These findings highlight the potential of instruction fine-tuning in automating structured bug report generation, reducing manual effort for developers and streamlining the software maintenance process.
Beyond Keywords: A Context-based Hybrid Approach to Mining Ethical Concern-related App Reviews
Nov 11, 2024



With the increasing proliferation of mobile applications in our everyday experiences, the concerns surrounding ethics have surged significantly. Users generally communicate their feedback, report issues, and suggest new functionalities in application (app) reviews, frequently emphasizing safety, privacy, and accountability concerns. Incorporating these reviews is essential to developing successful products. However, app reviews related to ethical concerns generally use domain-specific language and are expressed using a more varied vocabulary. Thus making automated ethical concern-related app review extraction a challenging and time-consuming effort. This study proposes a novel Natural Language Processing (NLP) based approach that combines Natural Language Inference (NLI), which provides a deep comprehension of language nuances, and a decoder-only (LLaMA-like) Large Language Model (LLM) to extract ethical concern-related app reviews at scale. Utilizing 43,647 app reviews from the mental health domain, the proposed methodology 1) Evaluates four NLI models to extract potential privacy reviews and compares the results of domain-specific privacy hypotheses with generic privacy hypotheses; 2) Evaluates four LLMs for classifying app reviews to privacy concerns; and 3) Uses the best NLI and LLM models further to extract new privacy reviews from the dataset. Results show that the DeBERTa-v3-base-mnli-fever-anli NLI model with domain-specific hypotheses yields the best performance, and Llama3.1-8B-Instruct LLM performs best in the classification of app reviews. Then, using NLI+LLM, an additional 1,008 new privacy-related reviews were extracted that were not identified through the keyword-based approach in previous research, thus demonstrating the effectiveness of the proposed approach.
Trustworthy and Responsible AI for Human-Centric Autonomous Decision-Making Systems
Sep 02, 2024Artificial Intelligence (AI) has paved the way for revolutionary decision-making processes, which if harnessed appropriately, can contribute to advancements in various sectors, from healthcare to economics. However, its black box nature presents significant ethical challenges related to bias and transparency. AI applications are hugely impacted by biases, presenting inconsistent and unreliable findings, leading to significant costs and consequences, highlighting and perpetuating inequalities and unequal access to resources. Hence, developing safe, reliable, ethical, and Trustworthy AI systems is essential. Our team of researchers working with Trustworthy and Responsible AI, part of the Transdisciplinary Scholarship Initiative within the University of Calgary, conducts research on Trustworthy and Responsible AI, including fairness, bias mitigation, reproducibility, generalization, interpretability, and authenticity. In this paper, we review and discuss the intricacies of AI biases, definitions, methods of detection and mitigation, and metrics for evaluating bias. We also discuss open challenges with regard to the trustworthiness and widespread application of AI across diverse domains of human-centric decision making, as well as guidelines to foster Responsible and Trustworthy AI models.
PRAGyan -- Connecting the Dots in Tweets
Jul 18, 2024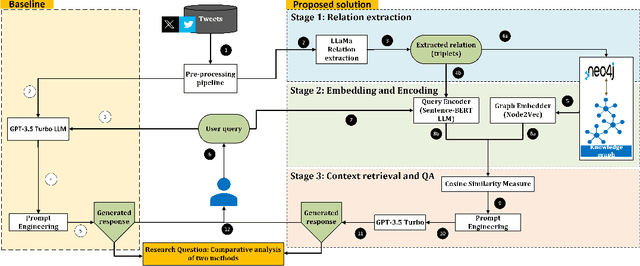



As social media platforms grow, understanding the underlying reasons behind events and statements becomes crucial for businesses, policymakers, and researchers. This research explores the integration of Knowledge Graphs (KGs) with Large Language Models (LLMs) to perform causal analysis of tweets dataset. The LLM aided analysis techniques often lack depth in uncovering the causes driving observed effects. By leveraging KGs and LLMs, which encode rich semantic relationships and temporal information, this study aims to uncover the complex interplay of factors influencing causal dynamics and compare the results obtained using GPT-3.5 Turbo. We employ a Retrieval-Augmented Generation (RAG) model, utilizing a KG stored in a Neo4j (a.k.a PRAGyan) data format, to retrieve relevant context for causal reasoning. Our approach demonstrates that the KG-enhanced LLM RAG can provide improved results when compared to the baseline LLM (GPT-3.5 Turbo) model as the source corpus increases in size. Our qualitative analysis highlights the advantages of combining KGs with LLMs for improved interpretability and actionable insights, facilitating informed decision-making across various domains. Whereas, quantitative analysis using metrics such as BLEU and cosine similarity show that our approach outperforms the baseline by 10\%.