 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftSAE: Dynamic Top-K Selection for Adaptive Sparse Autoencoders
May 07, 2026Sparse Autoencoders (SAEs) have become an important tool in mechanistic interpretability, helping to analyze internal representations in both Large Language Models (LLMs) and Vision Transformers (ViTs). By decomposing polysemantic activations into sparse sets of monosemantic features, SAEs aim to translate neural network computations into human-understandable concepts. However, common architectures such as TopK SAEs rely on a fixed sparsity level. They enforce the same number of active features (K) across all inputs, ignoring the varying complexity of real-world data. Natural data often lies on manifolds with varying local intrinsic dimensionality, meaning the number of relevant factors can change significantly across samples. This suggests that a fixed sparsity level is not optimal. Simple inputs may require only a few features, while more complex ones need more expressive representations. Using a constant K can therefore introduce noise in simple cases or miss important structure in more complex ones. To address this issue, we propose SoftSAE, a sparse autoencoder with a Dynamic Top-K selection mechanism. Our method uses a differentiable Soft Top-K operator to learn an input-dependent sparsity level k. This allows the model to adjust the number of active features based on the complexity of each input. As a result, the representation better matches the structure of the data, and the explanation length reflects the amount of information in the input. Experimental results confirm that SoftSAE not only finds meaningful features, but also selects the right number of features for each concept. The source code is available at: https://anonymous.4open.science/r/SoftSAE-8F71/.
Adapting Vision-Language Models for E-commerce Understanding at Scale
Feb 12, 2026E-commerce product understanding demands by nature, strong multimodal comprehension from text, images, and structured attributes. General-purpose Vision-Language Models (VLMs) enable generalizable multimodal latent modelling, yet there is no documented, well-known strategy for adapting them to the attribute-centric, multi-image, and noisy nature of e-commerce data, without sacrificing general performance. In this work, we show through a large-scale experimental study, how targeted adaptation of general VLMs can substantially improve e-commerce performance while preserving broad multimodal capabilities. Furthermore, we propose a novel extensive evaluation suite covering deep product understanding, strict instruction following, and dynamic attribute extraction.
QuantumGS: Quantum Encoding Framework for Gaussian Splatting
Feb 04, 2026Recent advances in neural rendering, particularly 3D Gaussian Splatting (3DGS), have enabled real-time rendering of complex scenes. However, standard 3DGS relies on spherical harmonics, which often struggle to accurately capture high-frequency view-dependent effects such as sharp reflections and transparency. While hybrid approaches like Viewing Direction Gaussian Splatting (VDGS) mitigate this limitation using classical Multi-Layer Perceptrons (MLPs), they remain limited by the expressivity of classical networks in low-parameter regimes. In this paper, we introduce QuantumGS, a novel hybrid framework that integrates Variational Quantum Circuits (VQC) into the Gaussian Splatting pipeline. We propose a unique encoding strategy that maps the viewing direction directly onto the Bloch sphere, leveraging the natural geometry of qubits to represent 3D directional data. By replacing classical color-modulating networks with quantum circuits generated via a hypernetwork or conditioning mechanism, we achieve higher expressivity and better generalization. Source code is available in the supplementary material. Code is available at https://github.com/gwilczynski95/QuantumGS
ReLAPSe: Reinforcement-Learning-trained Adversarial Prompt Search for Erased concepts in unlearned diffusion models
Jan 30, 2026Machine unlearning is a key defense mechanism for removing unauthorized concepts from text-to-image diffusion models, yet recent evidence shows that latent visual information often persists after unlearning. Existing adversarial approaches for exploiting this leakage are constrained by fundamental limitations: optimization-based methods are computationally expensive due to per-instance iterative search. At the same time, reasoning-based and heuristic techniques lack direct feedback from the target model's latent visual representations. To address these challenges, we introduce ReLAPSe, a policy-based adversarial framework that reformulates concept restoration as a reinforcement learning problem. ReLAPSe trains an agent using Reinforcement Learning with Verifiable Rewards (RLVR), leveraging the diffusion model's noise prediction loss as a model-intrinsic and verifiable feedback signal. This closed-loop design directly aligns textual prompt manipulation with latent visual residuals, enabling the agent to learn transferable restoration strategies rather than optimizing isolated prompts. By pioneering the shift from per-instance optimization to global policy learning, ReLAPSe achieves efficient, near-real-time recovery of fine-grained identities and styles across multiple state-of-the-art unlearning methods, providing a scalable tool for rigorous red-teaming of unlearned diffusion models. Some experimental evaluations involve sensitive visual concepts, such as nudity. Code is available at https://github.com/gmum/ReLaPSe
CLIPGaussian: Universal and Multimodal Style Transfer Based on Gaussian Splatting
May 28, 2025
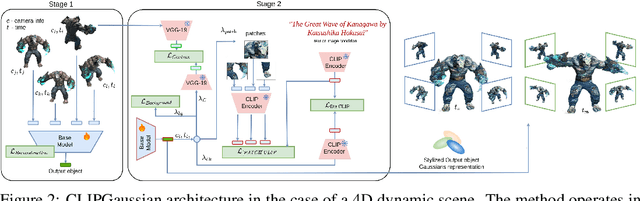


Gaussian Splatting (GS) has recently emerged as an efficient representation for rendering 3D scenes from 2D images and has been extended to images, videos, and dynamic 4D content. However, applying style transfer to GS-based representations, especially beyond simple color changes, remains challenging. In this work, we introduce CLIPGaussians, the first unified style transfer framework that supports text- and image-guided stylization across multiple modalities: 2D images, videos, 3D objects, and 4D scenes. Our method operates directly on Gaussian primitives and integrates into existing GS pipelines as a plug-in module, without requiring large generative models or retraining from scratch. CLIPGaussians approach enables joint optimization of color and geometry in 3D and 4D settings, and achieves temporal coherence in videos, while preserving a model size. We demonstrate superior style fidelity and consistency across all tasks, validating CLIPGaussians as a universal and efficient solution for multimodal style transfer.
CEC-MMR: Cross-Entropy Clustering Approach to Multi-Modal Regression
Apr 09, 2025In practical applications of regression analysis, it is not uncommon to encounter a multitude of values for each attribute. In such a situation, the univariate distribution, which is typically Gaussian, is suboptimal because the mean may be situated between modes, resulting in a predicted value that differs significantly from the actual data. Consequently, to address this issue, a mixture distribution with parameters learned by a neural network, known as a Mixture Density Network (MDN), is typically employed. However, this approach has an important inherent limitation, in that it is not feasible to ascertain the precise number of components with a reasonable degree of accuracy. In this paper, we introduce CEC-MMR, a novel approach based on Cross-Entropy Clustering (CEC), which allows for the automatic detection of the number of components in a regression problem. Furthermore, given an attribute and its value, our method is capable of uniquely identifying it with the underlying component. The experimental results demonstrate that CEC-MMR yields superior outcomes compared to classical MDNs.
MeshSplats: Mesh-Based Rendering with Gaussian Splatting Initialization
Feb 11, 2025Gaussian Splatting (GS) is a recent and pivotal technique in 3D computer graphics. GS-based algorithms almost always bypass classical methods such as ray tracing, which offers numerous inherent advantages for rendering. For example, ray tracing is able to handle incoherent rays for advanced lighting effects, including shadows and reflections. To address this limitation, we introduce MeshSplats, a method which converts GS to a mesh-like format. Following the completion of training, MeshSplats transforms Gaussian elements into mesh faces, enabling rendering using ray tracing methods with all their associated benefits. Our model can be utilized immediately following transformation, yielding a mesh of slightly reduced quality without additional training. Furthermore, we can enhance the reconstruction quality through the application of a dedicated optimization algorithm that operates on mesh faces rather than Gaussian components. The efficacy of our method is substantiated by experimental results, underscoring its extensive applications in computer graphics and image processing.
Tight Bounds on Jensen's Gap: Novel Approach with Applications in Generative Modeling
Feb 06, 2025Among various mathematical tools of particular interest are those that provide a common basis for researchers in different scientific fields. One of them is Jensen's inequality, which states that the expectation of a convex function is greater than or equal to the function evaluated at the expectation. The resulting difference, known as Jensen's gap, became the subject of investigation by both the statistical and machine learning communities. Among many related topics, finding lower and upper bounds on Jensen's gap (under different assumptions on the underlying function and distribution) has recently become a problem of particular interest. In our paper, we take another step in this direction by providing a novel general and mathematically rigorous technique, motivated by the recent results of Struski et al. (2023). In addition, by studying in detail the case of the logarithmic function and the log-normal distribution, we explore a method for tightly estimating the log-likelihood of generative models trained on real-world datasets. Furthermore, we present both analytical and experimental arguments in support of the superiority of our approach in comparison to existing state-of-the-art solutions, contingent upon fulfillment of the criteria set forth by theoretical studies and corresponding experiments on synthetic data.
RaySplats: Ray Tracing based Gaussian Splatting
Jan 31, 2025
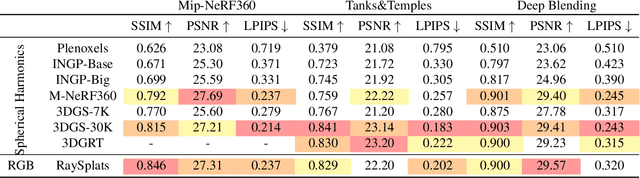
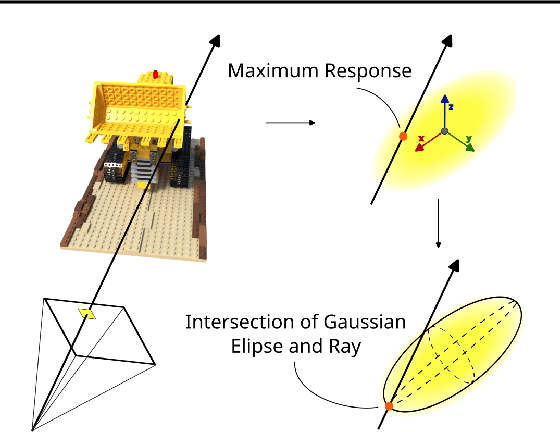

3D Gaussian Splatting (3DGS) is a process that enables the direct creation of 3D objects from 2D images. This representation offers numerous advantages, including rapid training and rendering. However, a significant limitation of 3DGS is the challenge of incorporating light and shadow reflections, primarily due to the utilization of rasterization rather than ray tracing for rendering. This paper introduces RaySplats, a model that employs ray-tracing based Gaussian Splatting. Rather than utilizing the projection of Gaussians, our method employs a ray-tracing mechanism, operating directly on Gaussian primitives represented by confidence ellipses with RGB colors. In practice, we compute the intersection between ellipses and rays to construct ray-tracing algorithms, facilitating the incorporation of meshes with Gaussian Splatting models and the addition of lights, shadows, and other related effects.
VeGaS: Video Gaussian Splatting
Nov 17, 2024Implicit Neural Representations (INRs) employ neural networks to approximate discrete data as continuous functions. In the context of video data, such models can be utilized to transform the coordinates of pixel locations along with frame occurrence times (or indices) into RGB color values. Although INRs facilitate effective compression, they are unsuitable for editing purposes. One potential solution is to use a 3D Gaussian Splatting (3DGS) based model, such as the Video Gaussian Representation (VGR), which is capable of encoding video as a multitude of 3D Gaussians and is applicable for numerous video processing operations, including editing. Nevertheless, in this case, the capacity for modification is constrained to a limited set of basic transformations. To address this issue, we introduce the Video Gaussian Splatting (VeGaS) model, which enables realistic modifications of video data. To construct VeGaS, we propose a novel family of Folded-Gaussian distributions designed to capture nonlinear dynamics in a video stream and model consecutive frames by 2D Gaussians obtained as respective conditional distributions. Our experiments demonstrate that VeGaS outperforms state-of-the-art solutions in frame reconstruction tasks and allows realistic modifications of video data. The code is available at: https://github.com/gmum/VeGaS.