 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Unlearning to UNBRANDING: A Benchmark for Trademark-Safe Text-to-Image Generation
Dec 15, 2025The rapid progress of text-to-image diffusion models raises significant concerns regarding the unauthorized reproduction of trademarked content. While prior work targets general concepts (e.g., styles, celebrities), it fails to address specific brand identifiers. Crucially, we note that brand recognition is multi-dimensional, extending beyond explicit logos to encompass distinctive structural features (e.g., a car's front grille). To tackle this, we introduce unbranding, a novel task for the fine-grained removal of both trademarks and subtle structural brand features, while preserving semantic coherence. To facilitate research, we construct a comprehensive benchmark dataset. Recognizing that existing brand detectors are limited to logos and fail to capture abstract trade dress (e.g., the shape of a Coca-Cola bottle), we introduce a novel evaluation metric based on Vision Language Models (VLMs). This VLM-based metric uses a question-answering framework to probe images for both explicit logos and implicit, holistic brand characteristics. Furthermore, we observe that as model fidelity increases, with newer systems (SDXL, FLUX) synthesizing brand identifiers more readily than older models (Stable Diffusion), the urgency of the unbranding challenge is starkly highlighted. Our results, validated by our VLM metric, confirm unbranding is a distinct, practically relevant problem requiring specialized techniques. Project Page: https://gmum.github.io/UNBRANDING/.
HuSc3D: Human Sculpture dataset for 3D object reconstruction
Jun 09, 2025

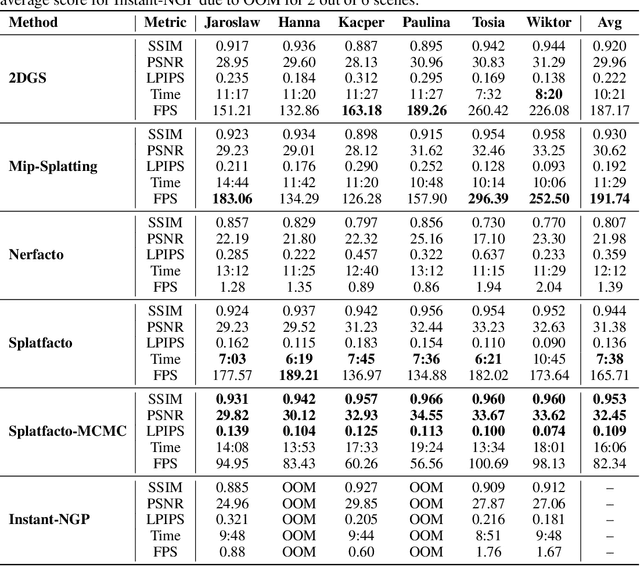

3D scene reconstruction from 2D images is one of the most important tasks in computer graphics. Unfortunately, existing datasets and benchmarks concentrate on idealized synthetic or meticulously captured realistic data. Such benchmarks fail to convey the inherent complexities encountered in newly acquired real-world scenes. In such scenes especially those acquired outside, the background is often dynamic, and by popular usage of cell phone cameras, there might be discrepancies in, e.g., white balance. To address this gap, we present HuSc3D, a novel dataset specifically designed for rigorous benchmarking of 3D reconstruction models under realistic acquisition challenges. Our dataset uniquely features six highly detailed, fully white sculptures characterized by intricate perforations and minimal textural and color variation. Furthermore, the number of images per scene varies significantly, introducing the additional challenge of limited training data for some instances alongside scenes with a standard number of views. By evaluating popular 3D reconstruction methods on this diverse dataset, we demonstrate the distinctiveness of HuSc3D in effectively differentiating model performance, particularly highlighting the sensitivity of methods to fine geometric details, color ambiguity, and varying data availability--limitations often masked by more conventional datasets.
Neural Surface Priors for Editable Gaussian Splatting
Nov 27, 2024



In computer graphics, there is a need to recover easily modifiable representations of 3D geometry and appearance from image data. We introduce a novel method for this task using 3D Gaussian Splatting, which enables intuitive scene editing through mesh adjustments. Starting with input images and camera poses, we reconstruct the underlying geometry using a neural Signed Distance Field and extract a high-quality mesh. Our model then estimates a set of Gaussians, where each component is flat, and the opacity is conditioned on the recovered neural surface. To facilitate editing, we produce a proxy representation that encodes information about the Gaussians' shape and position. Unlike other methods, our pipeline allows modifications applied to the extracted mesh to be propagated to the proxy representation, from which we recover the updated parameters of the Gaussians. This effectively transfers the mesh edits back to the recovered appearance representation. By leveraging mesh-guided transformations, our approach simplifies 3D scene editing and offers improvements over existing methods in terms of usability and visual fidelity of edits. The complete source code for this project can be accessed at \url{https://github.com/WJakubowska/NeuralSurfacePriors}
PR-ENDO: Physically Based Relightable Gaussian Splatting for Endoscopy
Nov 19, 2024



Endoscopic procedures are crucial for colorectal cancer diagnosis, and three-dimensional reconstruction of the environment for real-time novel-view synthesis can significantly enhance diagnosis. We present PR-ENDO, a framework that leverages 3D Gaussian Splatting within a physically based, relightable model tailored for the complex acquisition conditions in endoscopy, such as restricted camera rotations and strong view-dependent illumination. By exploiting the connection between the camera and light source, our approach introduces a relighting model to capture the intricate interactions between light and tissue using physically based rendering and MLP. Existing methods often produce artifacts and inconsistencies under these conditions, which PR-ENDO overcomes by incorporating a specialized diffuse MLP that utilizes light angles and normal vectors, achieving stable reconstructions even with limited training camera rotations. We benchmarked our framework using a publicly available dataset and a newly introduced dataset with wider camera rotations. Our methods demonstrated superior image quality compared to baseline approaches.
VeGaS: Video Gaussian Splatting
Nov 17, 2024Implicit Neural Representations (INRs) employ neural networks to approximate discrete data as continuous functions. In the context of video data, such models can be utilized to transform the coordinates of pixel locations along with frame occurrence times (or indices) into RGB color values. Although INRs facilitate effective compression, they are unsuitable for editing purposes. One potential solution is to use a 3D Gaussian Splatting (3DGS) based model, such as the Video Gaussian Representation (VGR), which is capable of encoding video as a multitude of 3D Gaussians and is applicable for numerous video processing operations, including editing. Nevertheless, in this case, the capacity for modification is constrained to a limited set of basic transformations. To address this issue, we introduce the Video Gaussian Splatting (VeGaS) model, which enables realistic modifications of video data. To construct VeGaS, we propose a novel family of Folded-Gaussian distributions designed to capture nonlinear dynamics in a video stream and model consecutive frames by 2D Gaussians obtained as respective conditional distributions. Our experiments demonstrate that VeGaS outperforms state-of-the-art solutions in frame reconstruction tasks and allows realistic modifications of video data. The code is available at: https://github.com/gmum/VeGaS.
HyperPlanes: Hypernetwork Approach to Rapid NeRF Adaptation
Feb 02, 2024Neural radiance fields (NeRFs) are a widely accepted standard for synthesizing new 3D object views from a small number of base images. However, NeRFs have limited generalization properties, which means that we need to use significant computational resources to train individual architectures for each item we want to represent. To address this issue, we propose a few-shot learning approach based on the hypernetwork paradigm that does not require gradient optimization during inference. The hypernetwork gathers information from the training data and generates an update for universal weights. As a result, we have developed an efficient method for generating a high-quality 3D object representation from a small number of images in a single step. This has been confirmed by direct comparison with the state-of-the-art solutions and a comprehensive ablation study.
Gaussian Splatting with NeRF-based Color and Opacity
Dec 22, 2023



Neural Radiance Fields (NeRFs) have demonstrated the remarkable potential of neural networks to capture the intricacies of 3D objects. By encoding the shape and color information within neural network weights, NeRFs excel at producing strikingly sharp novel views of 3D objects. Recently, numerous generalizations of NeRFs utilizing generative models have emerged, expanding its versatility. In contrast, Gaussian Splatting (GS) offers a similar renders quality with faster training and inference as it does not need neural networks to work. We encode information about the 3D objects in the set of Gaussian distributions that can be rendered in 3D similarly to classical meshes. Unfortunately, GS are difficult to condition since they usually require circa hundred thousand Gaussian components. To mitigate the caveats of both models, we propose a hybrid model that uses GS representation of the 3D object's shape and NeRF-based encoding of color and opacity. Our model uses Gaussian distributions with trainable positions (i.e. means of Gaussian), shape (i.e. covariance of Gaussian), color and opacity, and neural network, which takes parameters of Gaussian and viewing direction to produce changes in color and opacity. Consequently, our model better describes shadows, light reflections, and transparency of 3D objects.