Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpoken dialect identification in Twitter using a multi-filter architecture
Paper and Code
Jun 05, 2020

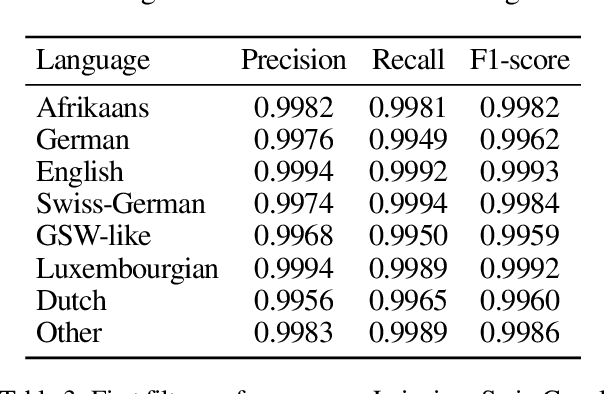
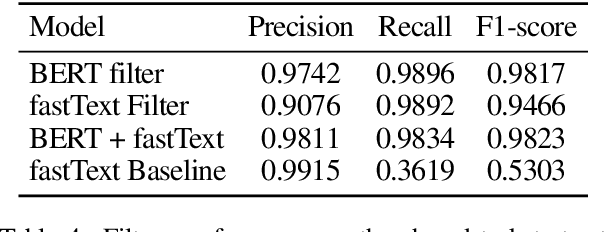
This paper presents our approach for SwissText & KONVENS 2020 shared task 2, which is a multi-stage neural model for Swiss German (GSW) identification on Twitter. Our model outputs either GSW or non-GSW and is not meant to be used as a generic language identifier. Our architecture consists of two independent filters where the first one favors recall, and the second one filter favors precision (both towards GSW). Moreover, we do not use binary models (GSW vs. not-GSW) in our filters but rather a multi-class classifier with GSW being one of the possible labels. Our model reaches F1-score of 0.982 on the test set of the shared task.
View paper on