 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View 3D Point Tracking
Aug 28, 2025We introduce the first data-driven multi-view 3D point tracker, designed to track arbitrary points in dynamic scenes using multiple camera views. Unlike existing monocular trackers, which struggle with depth ambiguities and occlusion, or prior multi-camera methods that require over 20 cameras and tedious per-sequence optimization, our feed-forward model directly predicts 3D correspondences using a practical number of cameras (e.g., four), enabling robust and accurate online tracking. Given known camera poses and either sensor-based or estimated multi-view depth, our tracker fuses multi-view features into a unified point cloud and applies k-nearest-neighbors correlation alongside a transformer-based update to reliably estimate long-range 3D correspondences, even under occlusion. We train on 5K synthetic multi-view Kubric sequences and evaluate on two real-world benchmarks: Panoptic Studio and DexYCB, achieving median trajectory errors of 3.1 cm and 2.0 cm, respectively. Our method generalizes well to diverse camera setups of 1-8 views with varying vantage points and video lengths of 24-150 frames. By releasing our tracker alongside training and evaluation datasets, we aim to set a new standard for multi-view 3D tracking research and provide a practical tool for real-world applications. Project page available at https://ethz-vlg.github.io/mvtracker.
Sim-to-Real Causal Transfer: A Metric Learning Approach to Causally-Aware Interaction Representations
Dec 07, 2023Modeling spatial-temporal interactions among neighboring agents is at the heart of multi-agent problems such as motion forecasting and crowd navigation. Despite notable progress, it remains unclear to which extent modern representations can capture the causal relationships behind agent interactions. In this work, we take an in-depth look at the causal awareness of these representations, from computational formalism to real-world practice. First, we cast doubt on the notion of non-causal robustness studied in the recent CausalAgents benchmark. We show that recent representations are already partially resilient to perturbations of non-causal agents, and yet modeling indirect causal effects involving mediator agents remains challenging. To address this challenge, we introduce a metric learning approach that regularizes latent representations with causal annotations. Our controlled experiments show that this approach not only leads to higher degrees of causal awareness but also yields stronger out-of-distribution robustness. To further operationalize it in practice, we propose a sim-to-real causal transfer method via cross-domain multi-task learning. Experiments on pedestrian datasets show that our method can substantially boost generalization, even in the absence of real-world causal annotations. We hope our work provides a new perspective on the challenges and potential pathways towards causally-aware representations of multi-agent interactions. Our code is available at https://github.com/socialcausality.
Segment Anything Meets Point Tracking
Jul 03, 2023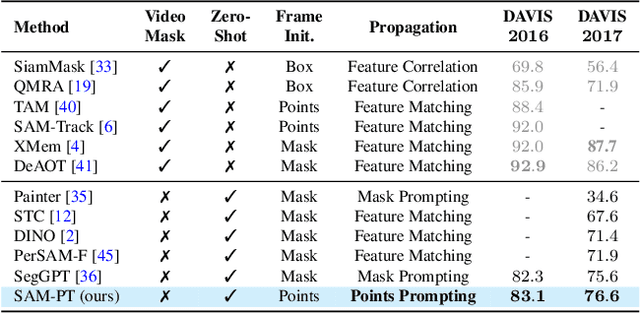
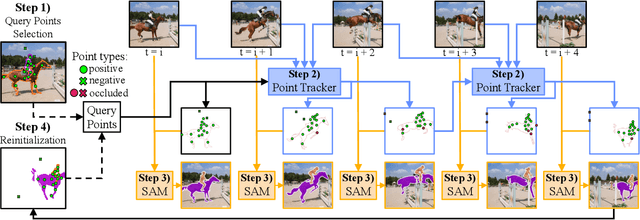


The Segment Anything Model (SAM) has established itself as a powerful zero-shot image segmentation model, employing interactive prompts such as points to generate masks. This paper presents SAM-PT, a method extending SAM's capability to tracking and segmenting anything in dynamic videos. SAM-PT leverages robust and sparse point selection and propagation techniques for mask generation, demonstrating that a SAM-based segmentation tracker can yield strong zero-shot performance across popular video object segmentation benchmarks, including DAVIS, YouTube-VOS, and MOSE. Compared to traditional object-centric mask propagation strategies, we uniquely use point propagation to exploit local structure information that is agnostic to object semantics. We highlight the merits of point-based tracking through direct evaluation on the zero-shot open-world Unidentified Video Objects (UVO) benchmark. To further enhance our approach, we utilize K-Medoids clustering for point initialization and track both positive and negative points to clearly distinguish the target object. We also employ multiple mask decoding passes for mask refinement and devise a point re-initialization strategy to improve tracking accuracy. Our code integrates different point trackers and video segmentation benchmarks and will be released at https://github.com/SysCV/sam-pt.
Using Focal Loss to Fight Shallow Heuristics: An Empirical Analysis of Modulated Cross-Entropy in Natural Language Inference
Nov 23, 2022



There is no such thing as a perfect dataset. In some datasets, deep neural networks discover underlying heuristics that allow them to take shortcuts in the learning process, resulting in poor generalization capability. Instead of using standard cross-entropy, we explore whether a modulated version of cross-entropy called focal loss can constrain the model so as not to use heuristics and improve generalization performance. Our experiments in natural language inference show that focal loss has a regularizing impact on the learning process, increasing accuracy on out-of-distribution data, but slightly decreasing performance on in-distribution data. Despite the improved out-of-distribution performance, we demonstrate the shortcomings of focal loss and its inferiority in comparison to the performance of methods such as unbiased focal loss and self-debiasing ensembles.