 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Augmentation and Evaluation Schemes for Semantic Image Synthesis
Dec 08, 2020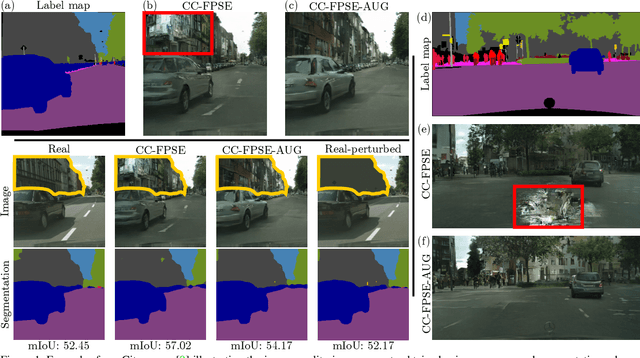

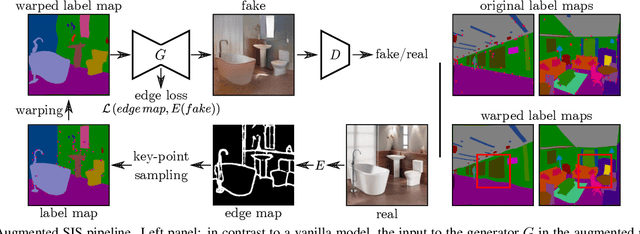
Despite data augmentation being a de facto technique for boosting the performance of deep neural networks, little attention has been paid to developing augmentation strategies for generative adversarial networks (GANs). To this end, we introduce a novel augmentation scheme designed specifically for GAN-based semantic image synthesis models. We propose to randomly warp object shapes in the semantic label maps used as an input to the generator. The local shape discrepancies between the warped and non-warped label maps and images enable the GAN to learn better the structural and geometric details of the scene and thus to improve the quality of generated images. While benchmarking the augmented GAN models against their vanilla counterparts, we discover that the quantification metrics reported in the previous semantic image synthesis studies are strongly biased towards specific semantic classes as they are derived via an external pre-trained segmentation network. We therefore propose to improve the established semantic image synthesis evaluation scheme by analyzing separately the performance of generated images on the biased and unbiased classes for the given segmentation network. Finally, we show strong quantitative and qualitative improvements obtained with our augmentation scheme, on both class splits, using state-of-the-art semantic image synthesis models across three different datasets. On average across COCO-Stuff, ADE20K and Cityscapes datasets, the augmented models outperform their vanilla counterparts by ~3 mIoU and ~10 FID points.
When are Neural ODE Solutions Proper ODEs?
Jul 30, 2020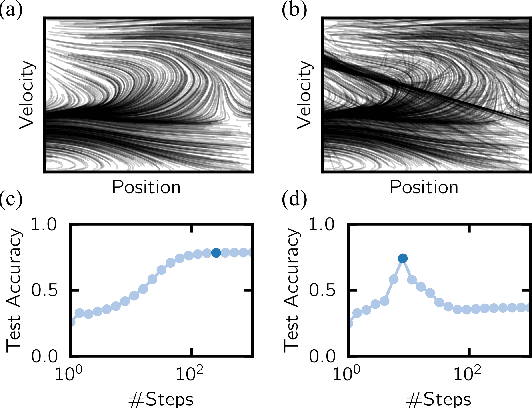
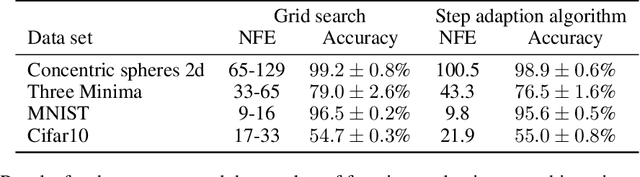

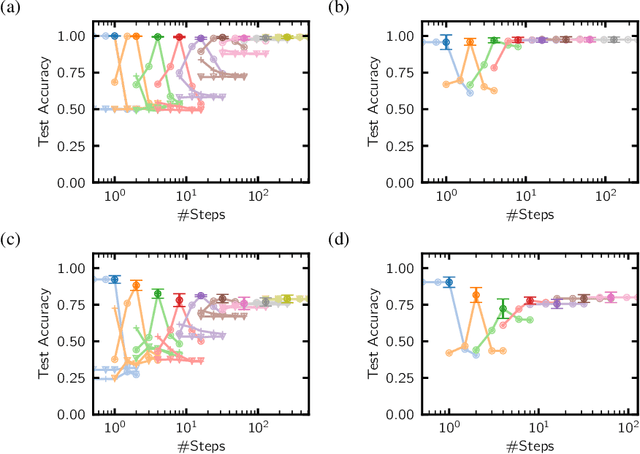
A key appeal of the recently proposed Neural Ordinary Differential Equation(ODE) framework is that it seems to provide a continuous-time extension of discrete residual neural networks. As we show herein, though, trained Neural ODE models actually depend on the specific numerical method used during training. If the trained model is supposed to be a flow generated from an ODE, it should be possible to choose another numerical solver with equal or smaller numerical error without loss of performance. We observe that if training relies on a solver with overly coarse discretization, then testing with another solver of equal or smaller numerical error results in a sharp drop in accuracy. In such cases, the combination of vector field and numerical method cannot be interpreted as a flow generated from an ODE, which arguably poses a fatal breakdown of the Neural ODE concept. We observe, however, that there exists a critical step size beyond which the training yields a valid ODE vector field. We propose a method that monitors the behavior of the ODE solver during training to adapt its step size, aiming to ensure a valid ODE without unnecessarily increasing computational cost. We verify this adaption algorithm on two common bench mark datasets as well as a synthetic dataset. Furthermore, we introduce a novel synthetic dataset in which the underlying ODE directly generates a classification task.
Grid Saliency for Context Explanations of Semantic Segmentation
Jul 30, 2019
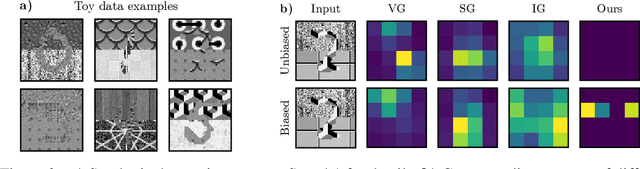
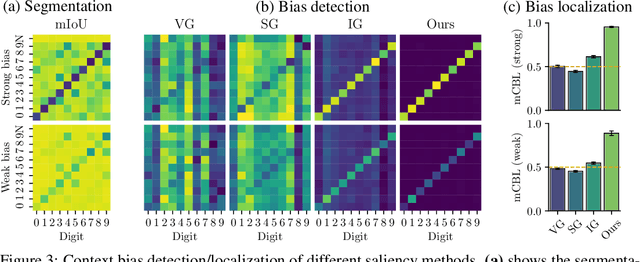
Recently, there has been a growing interest in developing saliency methods that provide visual explanations of network predictions. Still, the usability of existing methods is limited to image classification models. To overcome this limitation, we extend the existing approaches to generate grid saliencies, which provide spatially coherent visual explanations for (pixel-level) dense prediction networks. As the proposed grid saliency allows to spatially disentangle the object and its context, we specifically explore its potential to produce context explanations for semantic segmentation networks, discovering which context most influences the class predictions inside a target object area. We investigate the effectiveness of grid saliency on a synthetic dataset with an artificially induced bias between objects and their context as well as on the real-world Cityscapes dataset using state-of-the-art segmentation networks. Our results show that grid saliency can be successfully used to provide easily interpretable context explanations and, moreover, can be employed for detecting and localizing contextual biases present in the data.
A Fast Statistical Method for Multilevel Thresholding in Wavelet Domain
Dec 30, 2010

An algorithm is proposed for the segmentation of image into multiple levels using mean and standard deviation in the wavelet domain. The procedure provides for variable size segmentation with bigger block size around the mean, and having smaller blocks at the ends of histogram plot of each horizontal, vertical and diagonal components, while for the approximation component it provides for finer block size around the mean, and larger blocks at the ends of histogram plot coefficients. It is found that the proposed algorithm has significantly less time complexity, achieves superior PSNR and Structural Similarity Measurement Index as compared to similar space domain algorithms[1]. In the process it highlights finer image structures not perceptible in the original image. It is worth emphasizing that after the segmentation only 16 (at threshold level 3) wavelet coefficients captures the significant variation of image.