 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEML Online Speech Activity Detection for the Fearless Steps Challenge Phase-III
Jun 21, 2021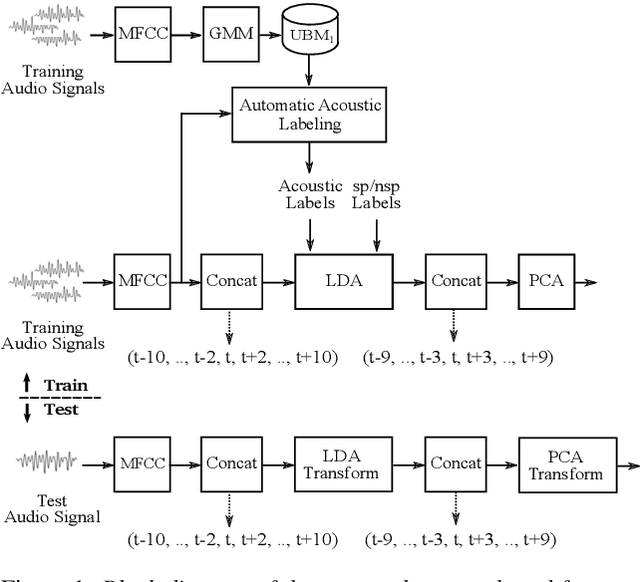

Speech Activity Detection (SAD), locating speech segments within an audio recording, is a main part of most speech technology applications. Robust SAD is usually more difficult in noisy conditions with varying signal-to-noise ratios (SNR). The Fearless Steps challenge has recently provided such data from the NASA Apollo-11 mission for different speech processing tasks including SAD. Most audio recordings are degraded by different kinds and levels of noise varying within and between channels. This paper describes the EML online algorithm for the most recent phase of this challenge. The proposed algorithm can be trained both in a supervised and unsupervised manner and assigns speech and non-speech labels at runtime approximately every 0.1 sec. The experimental results show a competitive accuracy on both development and evaluation datasets with a real-time factor of about 0.002 using a single CPU machine.
EML System Description for VoxCeleb Speaker Diarization Challenge 2020
Oct 23, 2020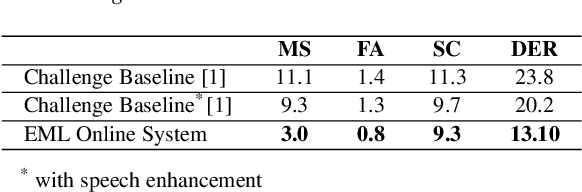
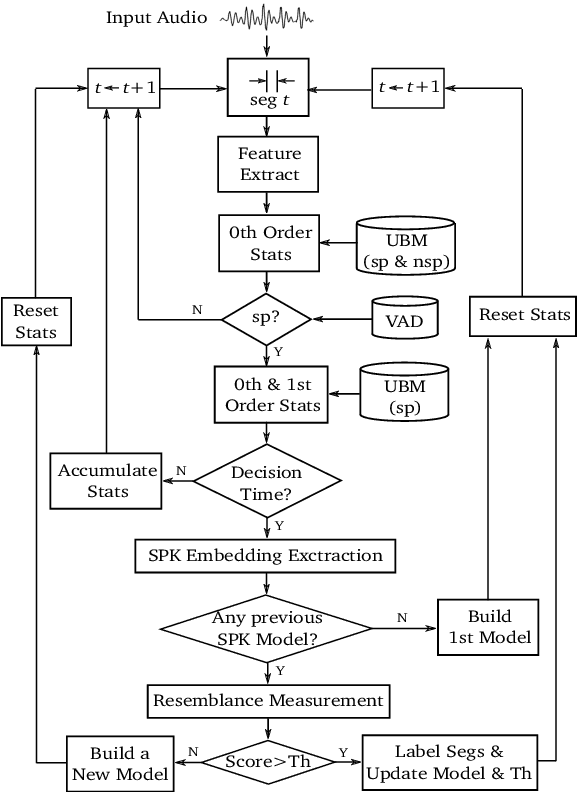
This technical report describes the EML submission to the first VoxCeleb speaker diarization challenge. Although the aim of the challenge has been the offline processing of the signals, the submitted system is basically the EML online algorithm which decides about the speaker labels in runtime approximately every 1.2 sec. For the first phase of the challenge, only VoxCeleb2 dev dataset was used for training. The results on the provided VoxConverse dev set show much better accuracy in terms of both DER and JER compared to the offline baseline provided in the challenge. The real-time factor of the whole diarization process is about 0.01 using a single CPU machine.
Deep Learning for Single and Multi-Session i-Vector Speaker Recognition
Dec 08, 2015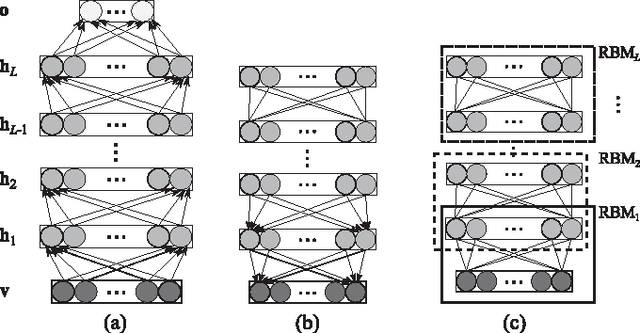
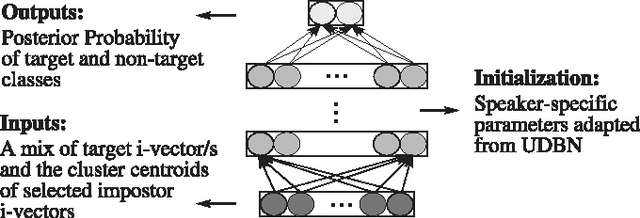

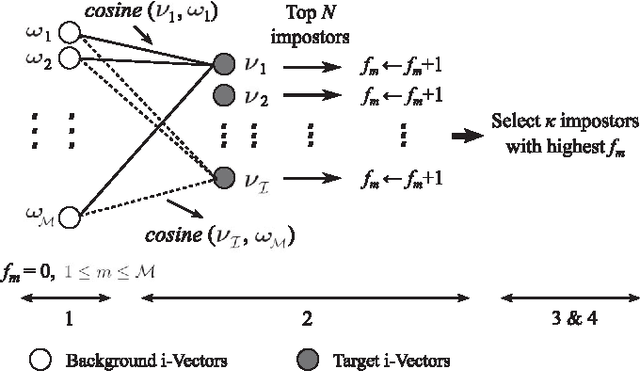
The promising performance of Deep Learning (DL) in speech recognition has motivated the use of DL in other speech technology applications such as speaker recognition. Given i-vectors as inputs, the authors proposed an impostor selection algorithm and a universal model adaptation process in a hybrid system based on Deep Belief Networks (DBN) and Deep Neural Networks (DNN) to discriminatively model each target speaker. In order to have more insight into the behavior of DL techniques in both single and multi-session speaker enrollment tasks, some experiments have been carried out in this paper in both scenarios. Additionally, the parameters of the global model, referred to as universal DBN (UDBN), are normalized before adaptation. UDBN normalization facilitates training DNNs specifically with more than one hidden layer. Experiments are performed on the NIST SRE 2006 corpus. It is shown that the proposed impostor selection algorithm and UDBN adaptation process enhance the performance of conventional DNNs 8-20 % and 16-20 % in terms of EER for the single and multi-session tasks, respectively. In both scenarios, the proposed architectures outperform the baseline systems obtaining up to 17 % reduction in EER.