 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Single and Multi-Session i-Vector Speaker Recognition
Paper and Code
Dec 08, 2015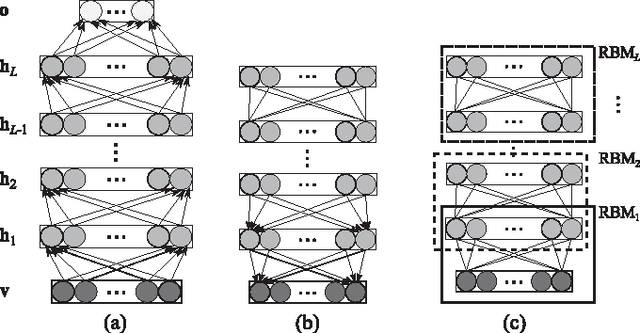
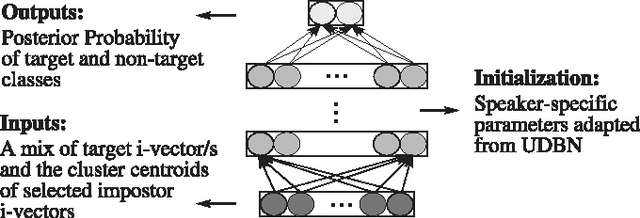

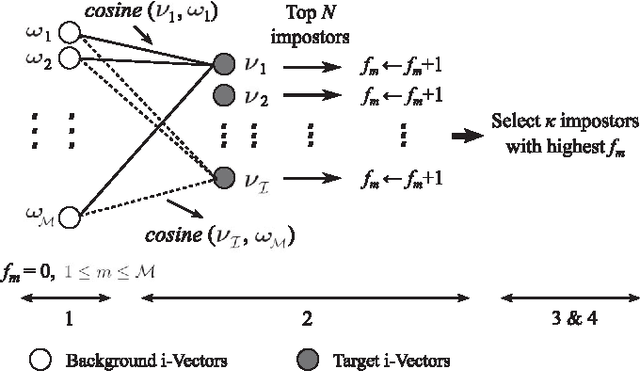
The promising performance of Deep Learning (DL) in speech recognition has motivated the use of DL in other speech technology applications such as speaker recognition. Given i-vectors as inputs, the authors proposed an impostor selection algorithm and a universal model adaptation process in a hybrid system based on Deep Belief Networks (DBN) and Deep Neural Networks (DNN) to discriminatively model each target speaker. In order to have more insight into the behavior of DL techniques in both single and multi-session speaker enrollment tasks, some experiments have been carried out in this paper in both scenarios. Additionally, the parameters of the global model, referred to as universal DBN (UDBN), are normalized before adaptation. UDBN normalization facilitates training DNNs specifically with more than one hidden layer. Experiments are performed on the NIST SRE 2006 corpus. It is shown that the proposed impostor selection algorithm and UDBN adaptation process enhance the performance of conventional DNNs 8-20 % and 16-20 % in terms of EER for the single and multi-session tasks, respectively. In both scenarios, the proposed architectures outperform the baseline systems obtaining up to 17 % reduction in EER.