 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagViB-6: A Diagnostic Benchmark Suite for Vision Models in the Presence of Shortcut and Generalization Opportunities
Aug 12, 2021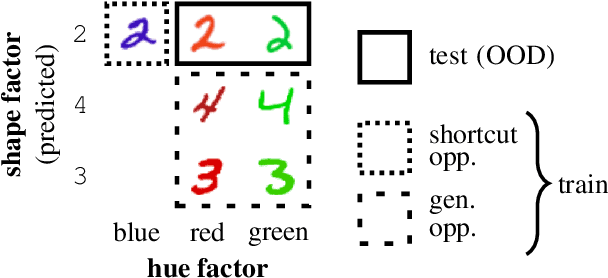


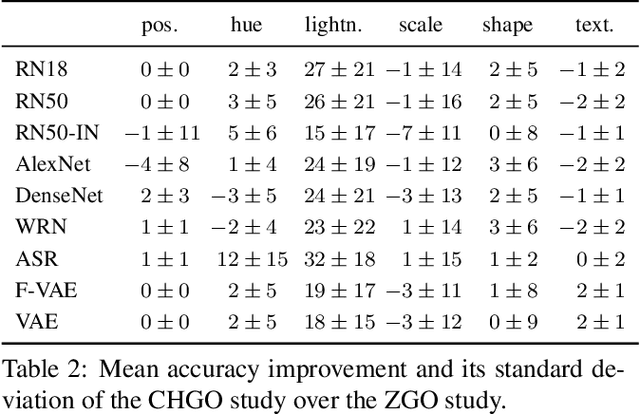
Common deep neural networks (DNNs) for image classification have been shown to rely on shortcut opportunities (SO) in the form of predictive and easy-to-represent visual factors. This is known as shortcut learning and leads to impaired generalization. In this work, we show that common DNNs also suffer from shortcut learning when predicting only basic visual object factors of variation (FoV) such as shape, color, or texture. We argue that besides shortcut opportunities, generalization opportunities (GO) are also an inherent part of real-world vision data and arise from partial independence between predicted classes and FoVs. We also argue that it is necessary for DNNs to exploit GO to overcome shortcut learning. Our core contribution is to introduce the Diagnostic Vision Benchmark suite DiagViB-6, which includes datasets and metrics to study a network's shortcut vulnerability and generalization capability for six independent FoV. In particular, DiagViB-6 allows controlling the type and degree of SO and GO in a dataset. We benchmark a wide range of popular vision architectures and show that they can exploit GO only to a limited extent.
Relational Generalized Few-Shot Learning
Jul 22, 2019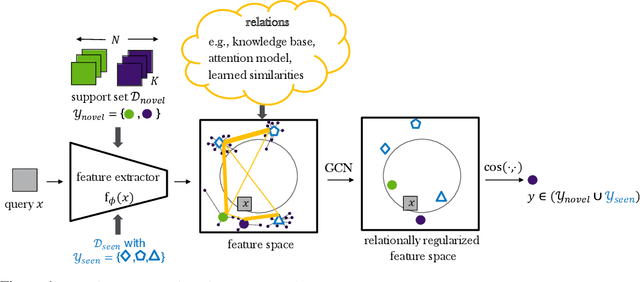
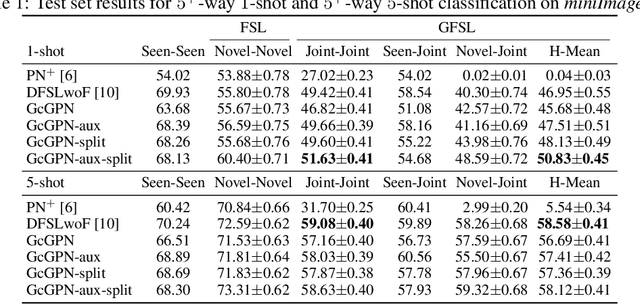
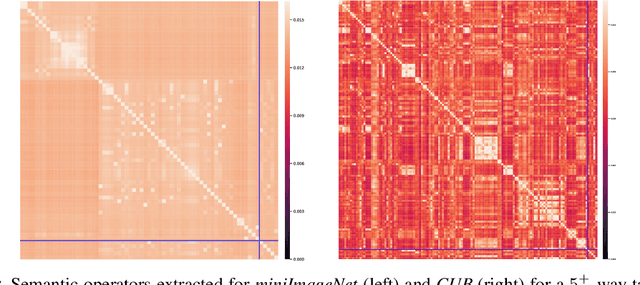
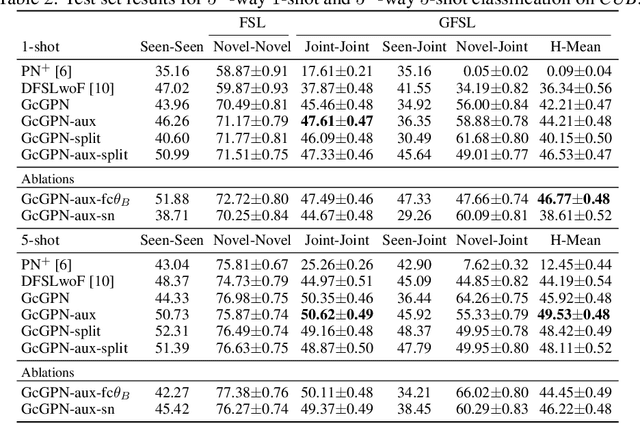
Transferring learned models to novel tasks is a challenging problem, particularly if only very few labeled examples are available. Although this few-shot learning setup has received a lot of attention recently, most proposed methods focus on discriminating novel classes only. Instead, we consider the extended setup of generalized few-shot learning (GFSL), where the model is required to perform classification on the joint label space consisting of both previously seen and novel classes. We propose a graph-based framework that explicitly models relationships between all seen and novel classes in the joint label space. Our model Graph-convolutional Global Prototypical Networks (GcGPN) incorporates these inter-class relations using graph-convolution in order to embed novel class representations into the existing space of previously seen classes in a globally consistent manner. Our approach ensures both fast adaptation and global discrimination, which is the major challenge in GFSL. We demonstrate the benefits of our model on two challenging benchmark datasets.
The Functional Neural Process
Jun 19, 2019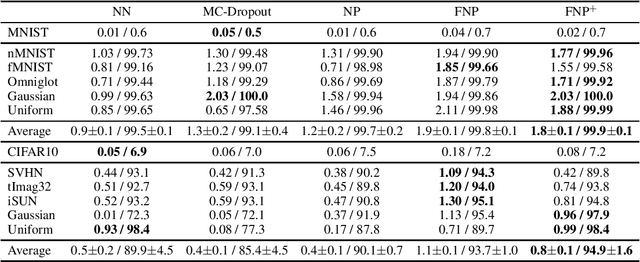
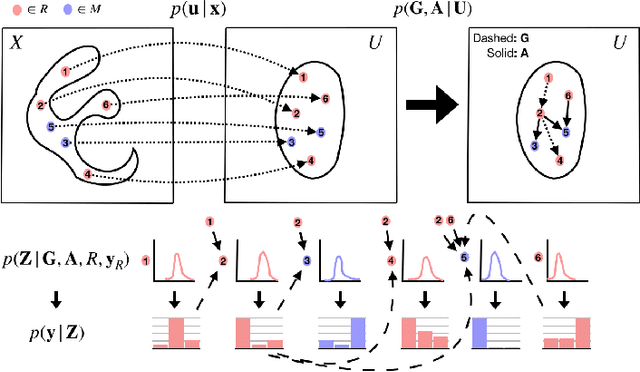
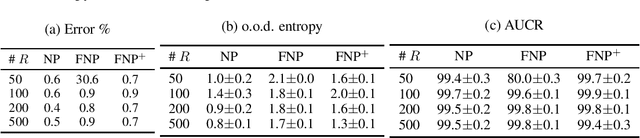

We present a new family of exchangeable stochastic processes, the Functional Neural Processes (FNPs). FNPs model distributions over functions by learning a graph of dependencies on top of latent representations of the points in the given dataset. In doing so, they define a Bayesian model without explicitly positing a prior distribution over latent global parameters; they instead adopt priors over the relational structure of the given dataset, a task that is much simpler. We show how we can learn such models from data, demonstrate that they are scalable to large datasets through mini-batch optimization and describe how we can make predictions for new points via their posterior predictive distribution. We experimentally evaluate FNPs on the tasks of toy regression and image classification and show that, when compared to baselines that employ global latent parameters, they offer both competitive predictions as well as more robust uncertainty estimates.