 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtlas 2 - Foundation models for clinical deployment
Jan 08, 2026Pathology foundation models substantially advanced the possibilities in computational pathology -- yet tradeoffs in terms of performance, robustness, and computational requirements remained, which limited their clinical deployment. In this report, we present Atlas 2, Atlas 2-B, and Atlas 2-S, three pathology vision foundation models which bridge these shortcomings by showing state-of-the-art performance in prediction performance, robustness, and resource efficiency in a comprehensive evaluation across eighty public benchmarks. Our models were trained on the largest pathology foundation model dataset to date comprising 5.5 million histopathology whole slide images, collected from three medical institutions Charité - Universtätsmedizin Berlin, LMU Munich, and Mayo Clinic.
Assumption violations in causal discovery and the robustness of score matching
Oct 20, 2023



When domain knowledge is limited and experimentation is restricted by ethical, financial, or time constraints, practitioners turn to observational causal discovery methods to recover the causal structure, exploiting the statistical properties of their data. Because causal discovery without further assumptions is an ill-posed problem, each algorithm comes with its own set of usually untestable assumptions, some of which are hard to meet in real datasets. Motivated by these considerations, this paper extensively benchmarks the empirical performance of recent causal discovery methods on observational i.i.d. data generated under different background conditions, allowing for violations of the critical assumptions required by each selected approach. Our experimental findings show that score matching-based methods demonstrate surprising performance in the false positive and false negative rate of the inferred graph in these challenging scenarios, and we provide theoretical insights into their performance. This work is also the first effort to benchmark the stability of causal discovery algorithms with respect to the values of their hyperparameters. Finally, we hope this paper will set a new standard for the evaluation of causal discovery methods and can serve as an accessible entry point for practitioners interested in the field, highlighting the empirical implications of different algorithm choices.
Toward Falsifying Causal Graphs Using a Permutation-Based Test
May 16, 2023

Understanding the causal relationships among the variables of a system is paramount to explain and control its behaviour. Inferring the causal graph from observational data without interventions, however, requires a lot of strong assumptions that are not always realistic. Even for domain experts it can be challenging to express the causal graph. Therefore, metrics that quantitatively assess the goodness of a causal graph provide helpful checks before using it in downstream tasks. Existing metrics provide an absolute number of inconsistencies between the graph and the observed data, and without a baseline, practitioners are left to answer the hard question of how many such inconsistencies are acceptable or expected. Here, we propose a novel consistency metric by constructing a surrogate baseline through node permutations. By comparing the number of inconsistencies with those on the surrogate baseline, we derive an interpretable metric that captures whether the DAG fits significantly better than random. Evaluating on both simulated and real data sets from various domains, including biology and cloud monitoring, we demonstrate that the true DAG is not falsified by our metric, whereas the wrong graphs given by a hypothetical user are likely to be falsified.
DiagViB-6: A Diagnostic Benchmark Suite for Vision Models in the Presence of Shortcut and Generalization Opportunities
Aug 12, 2021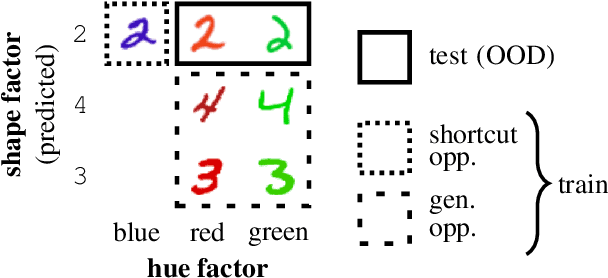


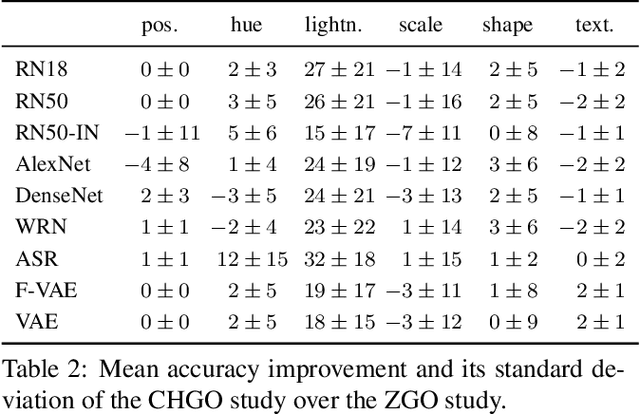
Common deep neural networks (DNNs) for image classification have been shown to rely on shortcut opportunities (SO) in the form of predictive and easy-to-represent visual factors. This is known as shortcut learning and leads to impaired generalization. In this work, we show that common DNNs also suffer from shortcut learning when predicting only basic visual object factors of variation (FoV) such as shape, color, or texture. We argue that besides shortcut opportunities, generalization opportunities (GO) are also an inherent part of real-world vision data and arise from partial independence between predicted classes and FoVs. We also argue that it is necessary for DNNs to exploit GO to overcome shortcut learning. Our core contribution is to introduce the Diagnostic Vision Benchmark suite DiagViB-6, which includes datasets and metrics to study a network's shortcut vulnerability and generalization capability for six independent FoV. In particular, DiagViB-6 allows controlling the type and degree of SO and GO in a dataset. We benchmark a wide range of popular vision architectures and show that they can exploit GO only to a limited extent.