 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Defer to Multiple Experts: Consistent Surrogate Losses, Confidence Calibration, and Conformal Ensembles
Oct 30, 2022We study the statistical properties of learning to defer (L2D) to multiple experts. In particular, we address the open problems of deriving a consistent surrogate loss, confidence calibration, and principled ensembling of experts. Firstly, we derive two consistent surrogates -- one based on a softmax parameterization, the other on a one-vs-all (OvA) parameterization -- that are analogous to the single expert losses proposed by Mozannar and Sontag (2020) and Verma and Nalisnick (2022), respectively. We then study the frameworks' ability to estimate P( m_j = y | x ), the probability that the jth expert will correctly predict the label for x. Theory shows the softmax-based loss causes mis-calibration to propagate between the estimates while the OvA-based loss does not (though in practice, we find there are trade offs). Lastly, we propose a conformal inference technique that chooses a subset of experts to query when the system defers. We perform empirical validation on tasks for galaxy, skin lesion, and hate speech classification.
Medical data wrangling with sequential variational autoencoders
Mar 12, 2021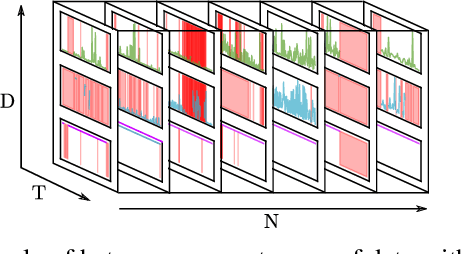

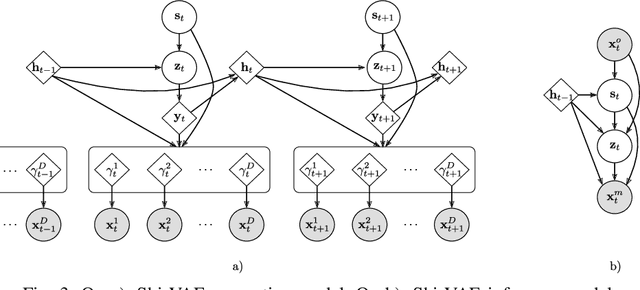
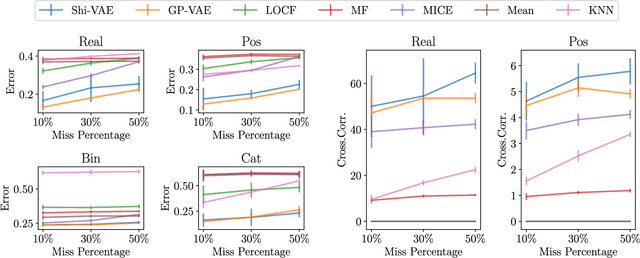
Medical data sets are usually corrupted by noise and missing data. These missing patterns are commonly assumed to be completely random, but in medical scenarios, the reality is that these patterns occur in bursts due to sensors that are off for some time or data collected in a misaligned uneven fashion, among other causes. This paper proposes to model medical data records with heterogeneous data types and bursty missing data using sequential variational autoencoders (VAEs). In particular, we propose a new methodology, the Shi-VAE, which extends the capabilities of VAEs to sequential streams of data with missing observations. We compare our model against state-of-the-art solutions in an intensive care unit database (ICU) and a dataset of passive human monitoring. Furthermore, we find that standard error metrics such as RMSE are not conclusive enough to assess temporal models and include in our analysis the cross-correlation between the ground truth and the imputed signal. We show that Shi-VAE achieves the best performance in terms of using both metrics, with lower computational complexity than the GP-VAE model, which is the state-of-the-art method for medical records.