 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemarked: A Strategy for Enhanced Abusive Speech Moderation through Counterspeech, Detoxification, and Message Management
Jun 27, 2024
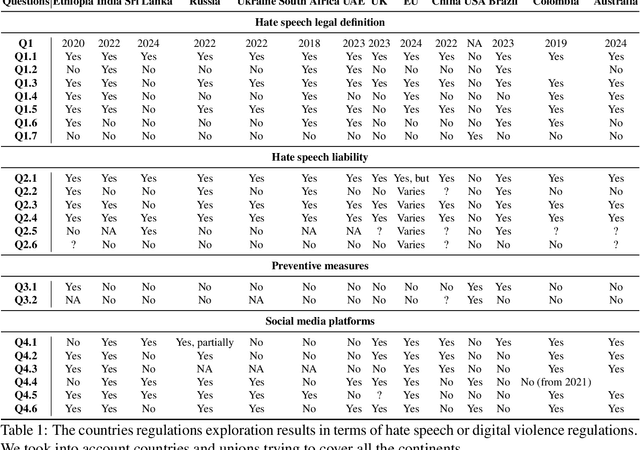
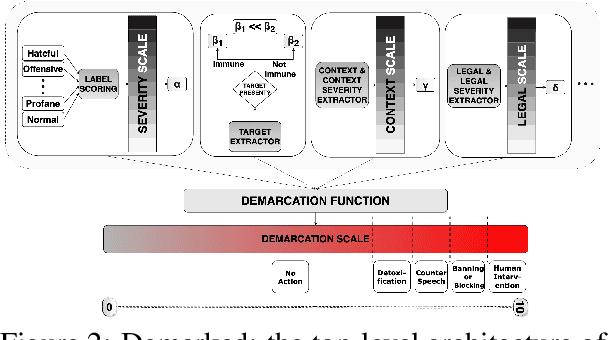

Despite regulations imposed by nations and social media platforms, such as recent EU regulations targeting digital violence, abusive content persists as a significant challenge. Existing approaches primarily rely on binary solutions, such as outright blocking or banning, yet fail to address the complex nature of abusive speech. In this work, we propose a more comprehensive approach called Demarcation scoring abusive speech based on four aspect -- (i) severity scale; (ii) presence of a target; (iii) context scale; (iv) legal scale -- and suggesting more options of actions like detoxification, counter speech generation, blocking, or, as a final measure, human intervention. Through a thorough analysis of abusive speech regulations across diverse jurisdictions, platforms, and research papers we highlight the gap in preventing measures and advocate for tailored proactive steps to combat its multifaceted manifestations. Our work aims to inform future strategies for effectively addressing abusive speech online.
Probing LLMs for hate speech detection: strengths and vulnerabilities
Oct 28, 2023



Recently efforts have been made by social media platforms as well as researchers to detect hateful or toxic language using large language models. However, none of these works aim to use explanation, additional context and victim community information in the detection process. We utilise different prompt variation, input information and evaluate large language models in zero shot setting (without adding any in-context examples). We select three large language models (GPT-3.5, text-davinci and Flan-T5) and three datasets - HateXplain, implicit hate and ToxicSpans. We find that on average including the target information in the pipeline improves the model performance substantially (~20-30%) over the baseline across the datasets. There is also a considerable effect of adding the rationales/explanations into the pipeline (~10-20%) over the baseline across the datasets. In addition, we further provide a typology of the error cases where these large language models fail to (i) classify and (ii) explain the reason for the decisions they take. Such vulnerable points automatically constitute 'jailbreak' prompts for these models and industry scale safeguard techniques need to be developed to make the models robust against such prompts.