 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Use XML: Revisiting Joint Translation and Label Projection
Mar 12, 2026Label projection is an effective technique for cross-lingual transfer, extending span-annotated datasets from a high-resource language to low-resource ones. Most approaches perform label projection as a separate step after machine translation, and prior work that combines the two reports degraded translation quality. We re-evaluate this claim with LabelPigeon, a novel framework that jointly performs translation and label projection via XML tags. We design a direct evaluation scheme for label projection, and find that LabelPigeon outperforms baselines and actively improves translation quality in 11 languages. We further assess translation quality across 203 languages and varying annotation complexity, finding consistent improvement attributed to additional fine-tuning. Finally, across 27 languages and three downstream tasks, we report substantial gains in cross-lingual transfer over comparable work, up to +39.9 F1 on NER. Overall, our results demonstrate that XML-tagged label projection provides effective and efficient label transfer without compromising translation quality.
Large Language Models Are Overparameterized Text Encoders
Oct 18, 2024



Large language models (LLMs) demonstrate strong performance as text embedding models when finetuned with supervised contrastive training. However, their large size balloons inference time and memory requirements. In this paper, we show that by pruning the last $p\%$ layers of an LLM before supervised training for only 1000 steps, we can achieve a proportional reduction in memory and inference time. We evaluate four different state-of-the-art LLMs on text embedding tasks and find that our method can prune up to 30\% of layers with negligible impact on performance and up to 80\% with only a modest drop. With only three lines of code, our method is easily implemented in any pipeline for transforming LLMs to text encoders. We also propose $\text{L}^3 \text{Prune}$, a novel layer-pruning strategy based on the model's initial loss that provides two optimal pruning configurations: a large variant with negligible performance loss and a small variant for resource-constrained settings. On average, the large variant prunes 21\% of the parameters with a $-0.3$ performance drop, and the small variant only suffers from a $-5.1$ decrease while pruning 74\% of the model. We consider these results strong evidence that LLMs are overparameterized for text embedding tasks, and can be easily pruned.
Advocating Character Error Rate for Multilingual ASR Evaluation
Oct 09, 2024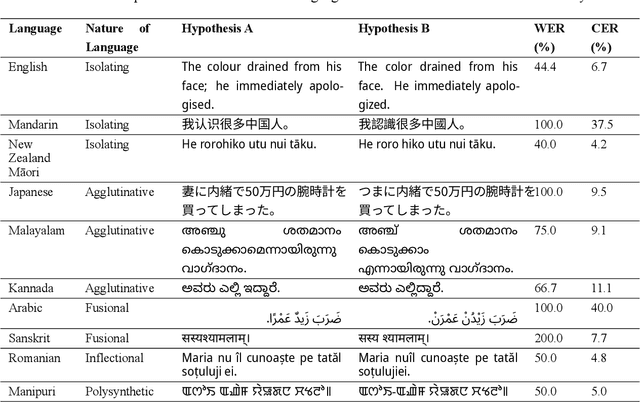



Automatic speech recognition (ASR) systems have traditionally been evaluated using English datasets, with the word error rate (WER) serving as the predominant metric. WER's simplicity and ease of interpretation have contributed to its widespread adoption, particularly for English. However, as ASR systems expand to multilingual contexts, WER fails in various ways, particularly with morphologically complex languages or those without clear word boundaries. Our work documents the limitations of WER as an evaluation metric and advocates for the character error rate (CER) as the primary metric in multilingual ASR evaluation. We show that CER avoids many of the challenges WER faces and exhibits greater consistency across writing systems. We support our proposition by conducting human evaluations of ASR transcriptions in three languages: Malayalam, English, and Arabic, which exhibit distinct morphological characteristics. We show that CER correlates more closely with human judgments than WER, even for English. To facilitate further research, we release our human evaluation dataset for future benchmarking of ASR metrics. Our findings suggest that CER should be prioritized, or at least supplemented, in multilingual ASR evaluations to account for the varying linguistic characteristics of different languages.
Fisher Mask Nodes for Language Model Merging
Mar 18, 2024Fine-tuning pre-trained models provides significant advantages in downstream performance. The ubiquitous nature of pre-trained models such as BERT and its derivatives in natural language processing has also led to a proliferation of task-specific fine-tuned models. As these models typically only perform one task well, additional training or ensembling is required in multi-task scenarios. The growing field of model merging provides a solution, dealing with the challenge of combining multiple task-specific models into a single multi-task model. In this study, we introduce a novel model merging method for Transformers, combining insights from previous work in Fisher-weighted averaging and the use of Fisher information in model pruning. Utilizing the Fisher information of mask nodes within the Transformer architecture, we devise a computationally efficient weighted-averaging scheme. Our method exhibits a regular and significant performance increase across various models in the BERT family, outperforming full-scale Fisher-weighted averaging in a fraction of the computational cost, with baseline performance improvements of up to +6.5 and a speedup of 57.4x in the biggest model. Our results prove the potential of our method in current multi-task learning environments and suggest its scalability and adaptability to new model architectures and learning scenarios.
IMaSC -- ICFOSS Malayalam Speech Corpus
Nov 23, 2022Modern text-to-speech (TTS) systems use deep learning to synthesize speech increasingly approaching human quality, but they require a database of high quality audio-text sentence pairs for training. Malayalam, the official language of the Indian state of Kerala and spoken by 35+ million people, is a low resource language in terms of available corpora for TTS systems. In this paper, we present IMaSC, a Malayalam text and speech corpora containing approximately 50 hours of recorded speech. With 8 speakers and a total of 34,473 text-audio pairs, IMaSC is larger than every other publicly available alternative. We evaluated the database by using it to train TTS models for each speaker based on a modern deep learning architecture. Via subjective evaluation, we show that our models perform significantly better in terms of naturalness compared to previous studies and publicly available models, with an average mean opinion score of 4.50, indicating that the synthesized speech is close to human quality.