 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvocating Character Error Rate for Multilingual ASR Evaluation
Oct 09, 2024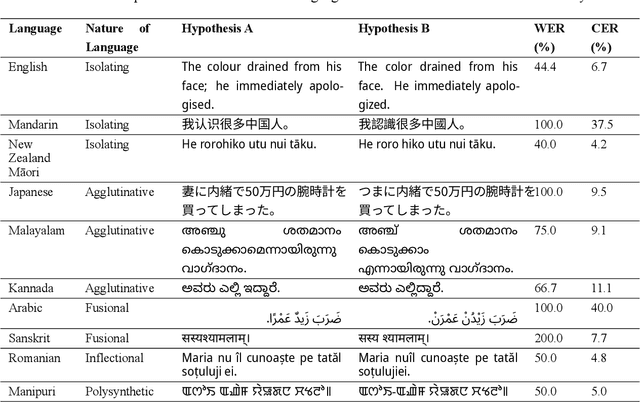



Automatic speech recognition (ASR) systems have traditionally been evaluated using English datasets, with the word error rate (WER) serving as the predominant metric. WER's simplicity and ease of interpretation have contributed to its widespread adoption, particularly for English. However, as ASR systems expand to multilingual contexts, WER fails in various ways, particularly with morphologically complex languages or those without clear word boundaries. Our work documents the limitations of WER as an evaluation metric and advocates for the character error rate (CER) as the primary metric in multilingual ASR evaluation. We show that CER avoids many of the challenges WER faces and exhibits greater consistency across writing systems. We support our proposition by conducting human evaluations of ASR transcriptions in three languages: Malayalam, English, and Arabic, which exhibit distinct morphological characteristics. We show that CER correlates more closely with human judgments than WER, even for English. To facilitate further research, we release our human evaluation dataset for future benchmarking of ASR metrics. Our findings suggest that CER should be prioritized, or at least supplemented, in multilingual ASR evaluations to account for the varying linguistic characteristics of different languages.
IMaSC -- ICFOSS Malayalam Speech Corpus
Nov 23, 2022Modern text-to-speech (TTS) systems use deep learning to synthesize speech increasingly approaching human quality, but they require a database of high quality audio-text sentence pairs for training. Malayalam, the official language of the Indian state of Kerala and spoken by 35+ million people, is a low resource language in terms of available corpora for TTS systems. In this paper, we present IMaSC, a Malayalam text and speech corpora containing approximately 50 hours of recorded speech. With 8 speakers and a total of 34,473 text-audio pairs, IMaSC is larger than every other publicly available alternative. We evaluated the database by using it to train TTS models for each speaker based on a modern deep learning architecture. Via subjective evaluation, we show that our models perform significantly better in terms of naturalness compared to previous studies and publicly available models, with an average mean opinion score of 4.50, indicating that the synthesized speech is close to human quality.