 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvocating Character Error Rate for Multilingual ASR Evaluation
Oct 09, 2024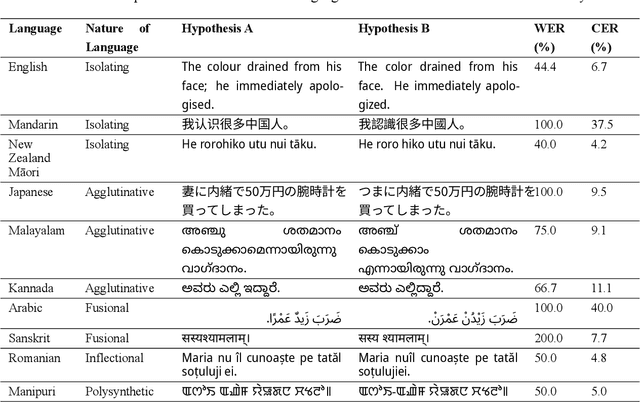



Automatic speech recognition (ASR) systems have traditionally been evaluated using English datasets, with the word error rate (WER) serving as the predominant metric. WER's simplicity and ease of interpretation have contributed to its widespread adoption, particularly for English. However, as ASR systems expand to multilingual contexts, WER fails in various ways, particularly with morphologically complex languages or those without clear word boundaries. Our work documents the limitations of WER as an evaluation metric and advocates for the character error rate (CER) as the primary metric in multilingual ASR evaluation. We show that CER avoids many of the challenges WER faces and exhibits greater consistency across writing systems. We support our proposition by conducting human evaluations of ASR transcriptions in three languages: Malayalam, English, and Arabic, which exhibit distinct morphological characteristics. We show that CER correlates more closely with human judgments than WER, even for English. To facilitate further research, we release our human evaluation dataset for future benchmarking of ASR metrics. Our findings suggest that CER should be prioritized, or at least supplemented, in multilingual ASR evaluations to account for the varying linguistic characteristics of different languages.
The Development of a Labelled te reo Māori-English Bilingual Database for Language Technology
Aug 21, 2022


Te reo M\=aori (referred to as M\=aori), New Zealand's indigenous language, is under-resourced in language technology. M\=aori speakers are bilingual, where M\=aori is code-switched with English. Unfortunately, there are minimal resources available for M\=aori language technology, language detection and code-switch detection between M\=aori-English pair. Both English and M\=aori use Roman-derived orthography making rule-based systems for detecting language and code-switching restrictive. Most M\=aori language detection is done manually by language experts. This research builds a M\=aori-English bilingual database of 66,016,807 words with word-level language annotation. The New Zealand Parliament Hansard debates reports were used to build the database. The language labels are assigned using language-specific rules and expert manual annotations. Words with the same spelling, but different meanings, exist for M\=aori and English. These words could not be categorised as M\=aori or English based on word-level language rules. Hence, manual annotations were necessary. An analysis reporting the various aspects of the database such as metadata, year-wise analysis, frequently occurring words, sentence length and N-grams is also reported. The database developed here is a valuable tool for future language and speech technology development for Aotearoa New Zealand. The methodology followed to label the database can also be followed by other low-resourced language pairs.
Visualising Model Training via Vowel Space for Text-To-Speech Systems
Aug 21, 2022


With the recent developments in speech synthesis via machine learning, this study explores incorporating linguistics knowledge to visualise and evaluate synthetic speech model training. If changes to the first and second formant (in turn, the vowel space) can be seen and heard in synthetic speech, this knowledge can inform speech synthesis technology developers. A speech synthesis model trained on a large General American English database was fine-tuned into a New Zealand English voice to identify if the changes in the vowel space of synthetic speech could be seen and heard. The vowel spaces at different intervals during the fine-tuning were analysed to determine if the model learned the New Zealand English vowel space. Our findings based on vowel space analysis show that we can visualise how a speech synthesis model learns the vowel space of the database it is trained on. Perception tests confirmed that humans could perceive when a speech synthesis model has learned characteristics of the speech database it is training on. Using the vowel space as an intermediary evaluation helps understand what sounds are to be added to the training database and build speech synthesis models based on linguistics knowledge.