 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Development of a Labelled te reo Māori-English Bilingual Database for Language Technology
Aug 21, 2022


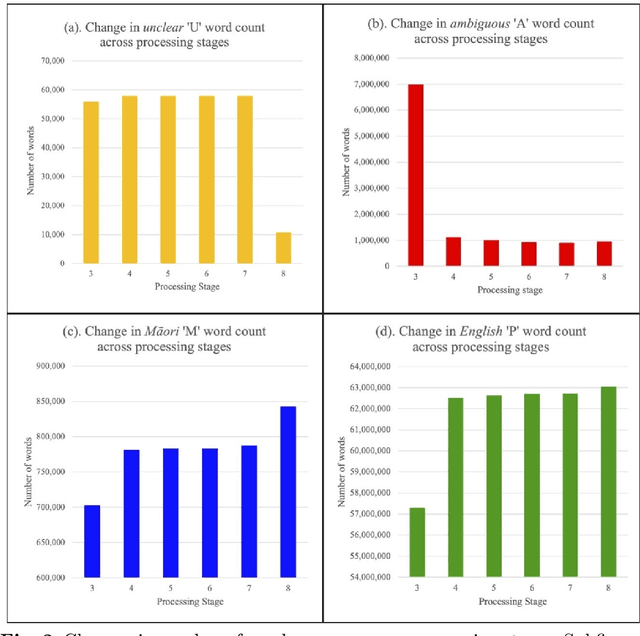
Te reo M\=aori (referred to as M\=aori), New Zealand's indigenous language, is under-resourced in language technology. M\=aori speakers are bilingual, where M\=aori is code-switched with English. Unfortunately, there are minimal resources available for M\=aori language technology, language detection and code-switch detection between M\=aori-English pair. Both English and M\=aori use Roman-derived orthography making rule-based systems for detecting language and code-switching restrictive. Most M\=aori language detection is done manually by language experts. This research builds a M\=aori-English bilingual database of 66,016,807 words with word-level language annotation. The New Zealand Parliament Hansard debates reports were used to build the database. The language labels are assigned using language-specific rules and expert manual annotations. Words with the same spelling, but different meanings, exist for M\=aori and English. These words could not be categorised as M\=aori or English based on word-level language rules. Hence, manual annotations were necessary. An analysis reporting the various aspects of the database such as metadata, year-wise analysis, frequently occurring words, sentence length and N-grams is also reported. The database developed here is a valuable tool for future language and speech technology development for Aotearoa New Zealand. The methodology followed to label the database can also be followed by other low-resourced language pairs.