 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualising Model Training via Vowel Space for Text-To-Speech Systems
Aug 21, 2022


With the recent developments in speech synthesis via machine learning, this study explores incorporating linguistics knowledge to visualise and evaluate synthetic speech model training. If changes to the first and second formant (in turn, the vowel space) can be seen and heard in synthetic speech, this knowledge can inform speech synthesis technology developers. A speech synthesis model trained on a large General American English database was fine-tuned into a New Zealand English voice to identify if the changes in the vowel space of synthetic speech could be seen and heard. The vowel spaces at different intervals during the fine-tuning were analysed to determine if the model learned the New Zealand English vowel space. Our findings based on vowel space analysis show that we can visualise how a speech synthesis model learns the vowel space of the database it is trained on. Perception tests confirmed that humans could perceive when a speech synthesis model has learned characteristics of the speech database it is training on. Using the vowel space as an intermediary evaluation helps understand what sounds are to be added to the training database and build speech synthesis models based on linguistics knowledge.
N-shot Palm Vein Verification Using Siamese Networks
Sep 27, 2021
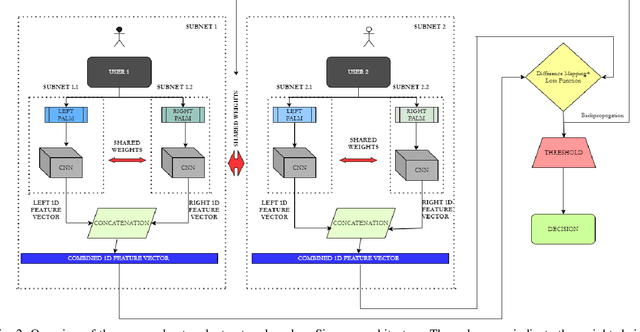
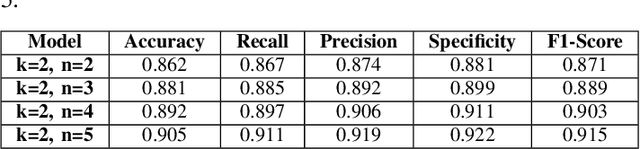

The use of deep learning methods to extract vascular biometric patterns from the palm surface has been of interest among researchers in recent years. In many biometric recognition tasks, there is a limit in the number of training samples. This is because of limited vein biometric databases being available for research. This restricts the application of deep learning methods to design algorithms that can effectively identify or authenticate people for vein recognition. This paper proposes an architecture using Siamese neural network structure for few shot palm vein identification. The proposed network uses images from both the palms and consists of two sub-nets that share weights to identify a person. The architecture performance was tested on the HK PolyU multi spectral palm vein database with limited samples. The results suggest that the method is effective since it has 91.9% precision, 91.1% recall, 92.2% specificity, 91.5%, F1-Score, and 90.5% accuracy values.