 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Profiling in LLM-Based Literary Translation: Systematic Shifts Across MT and Post-Editing
Jun 08, 2026This paper investigates whether LLM translations exhibit identifiable emotional profiles and how post-editing reshapes them toward human-like norms. We compare LLM translations of Margaret Atwood's Oryx and Crake with their post-edited versions and a human translation, using a large-scale corpus of contemporary Italian science-fiction as a baseline. We examine emotion through lexicon-based and multilingual modeling, conducting a fine-grained analysis of emotional variation across systems. We find that MT systems introduce model-specific and statistically significant emotional fingerprints across translations, leading to a limited preservation of an author's voice.
Data-Efficient Domain Adaptation for LLM-based MT using Contrastive Preference Optimization
Oct 31, 2025LLMs often require adaptation to domain-specific requirements, a process that can be expensive when relying solely on SFT. We present an empirical study on applying CPO to simulate a post-editing workflow for data-efficient domain adaptation. Our approach synthesizes preference pairs by treating the base model's own raw output as the 'rejected' translation and the human-approved TM entry as the 'chosen' one. This method provides direct feedback on the model's current knowledge, guiding it to align with domain-specific standards. Experiments in English-Brazilian Portuguese and English-Korean show that, by using just 14.7k preference pairs, the model achieves performance close to that of a model trained on 160k+ samples with SFT, demonstrating significant data efficiency. Although we showcase its effectiveness in MT, this application of CPO naturally generalizes to other generative tasks where a model's initial drafts can serve as a contrastive signal against a golden reference.
Audio-Based Crowd-Sourced Evaluation of Machine Translation Quality
Sep 17, 2025Machine Translation (MT) has achieved remarkable performance, with growing interest in speech translation and multimodal approaches. However, despite these advancements, MT quality assessment remains largely text centric, typically relying on human experts who read and compare texts. Since many real-world MT applications (e.g Google Translate Voice Mode, iFLYTEK Translator) involve translation being spoken rather printed or read, a more natural way to assess translation quality would be through speech as opposed text-only evaluations. This study compares text-only and audio-based evaluations of 10 MT systems from the WMT General MT Shared Task, using crowd-sourced judgments collected via Amazon Mechanical Turk. We additionally, performed statistical significance testing and self-replication experiments to test reliability and consistency of audio-based approach. Crowd-sourced assessments based on audio yield rankings largely consistent with text only evaluations but, in some cases, identify significant differences between translation systems. We attribute this to speech richer, more natural modality and propose incorporating speech-based assessments into future MT evaluation frameworks.
Long-context Reference-based MT Quality Estimation
Sep 17, 2025In this paper, we present our submission to the Tenth Conference on Machine Translation (WMT25) Shared Task on Automated Translation Quality Evaluation. Our systems are built upon the COMET framework and trained to predict segment-level Error Span Annotation (ESA) scores using augmented long-context data. To construct long-context training data, we concatenate in-domain, human-annotated sentences and compute a weighted average of their scores. We integrate multiple human judgment datasets (MQM, SQM, and DA) by normalising their scales and train multilingual regression models to predict quality scores from the source, hypothesis, and reference translations. Experimental results show that incorporating long-context information improves correlations with human judgments compared to models trained only on short segments.
Context-Aware Monolingual Human Evaluation of Machine Translation
Apr 10, 2025This paper explores the potential of context-aware monolingual human evaluation for assessing machine translation (MT) when no source is given for reference. To this end, we compare monolingual with bilingual evaluations (with source text), under two scenarios: the evaluation of a single MT system, and the comparative evaluation of pairwise MT systems. Four professional translators performed both monolingual and bilingual evaluations by assigning ratings and annotating errors, and providing feedback on their experience. Our findings suggest that context-aware monolingual human evaluation achieves comparable outcomes to human bilingual evaluations, and suggest the feasibility and potential of monolingual evaluation as an efficient approach to assessing MT.
Synthetic Fluency: Hallucinations, Confabulations, and the Creation of Irish Words in LLM-Generated Translations
Apr 10, 2025This study examines hallucinations in Large Language Model (LLM) translations into Irish, specifically focusing on instances where the models generate novel, non-existent words. We classify these hallucinations within verb and noun categories, identifying six distinct patterns among the latter. Additionally, we analyse whether these hallucinations adhere to Irish morphological rules and what linguistic tendencies they exhibit. Our findings show that while both GPT-4.o and GPT-4.o Mini produce similar types of hallucinations, the Mini model generates them at a significantly higher frequency. Beyond classification, the discussion raises speculative questions about the implications of these hallucinations for the Irish language. Rather than seeking definitive answers, we offer food for thought regarding the increasing use of LLMs and their potential role in shaping Irish vocabulary and linguistic evolution. We aim to prompt discussion on how such technologies might influence language over time, particularly in the context of low-resource, morphologically rich languages.
A Set of Recommendations for Assessing Human-Machine Parity in Language Translation
Apr 03, 2020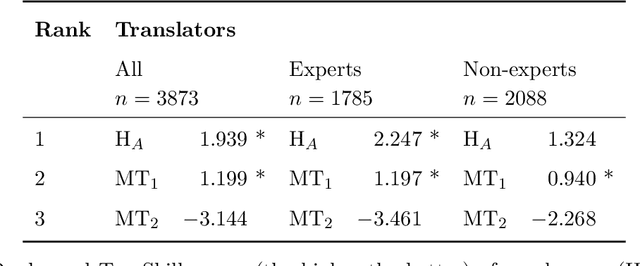

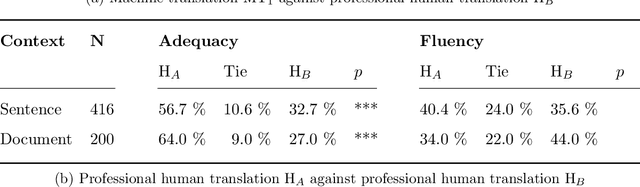
The quality of machine translation has increased remarkably over the past years, to the degree that it was found to be indistinguishable from professional human translation in a number of empirical investigations. We reassess Hassan et al.'s 2018 investigation into Chinese to English news translation, showing that the finding of human-machine parity was owed to weaknesses in the evaluation design - which is currently considered best practice in the field. We show that the professional human translations contained significantly fewer errors, and that perceived quality in human evaluation depends on the choice of raters, the availability of linguistic context, and the creation of reference translations. Our results call for revisiting current best practices to assess strong machine translation systems in general and human-machine parity in particular, for which we offer a set of recommendations based on our empirical findings.
Attaining the Unattainable? Reassessing Claims of Human Parity in Neural Machine Translation
Aug 30, 2018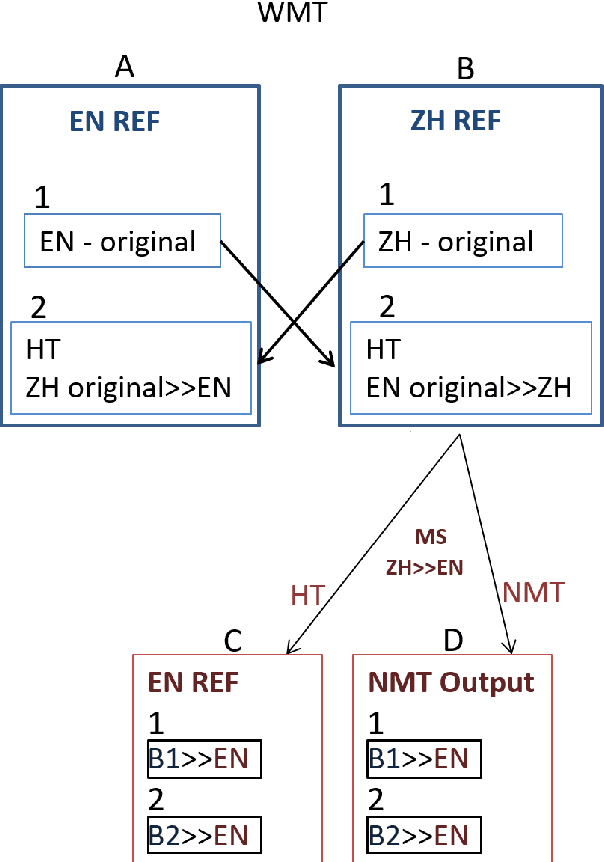
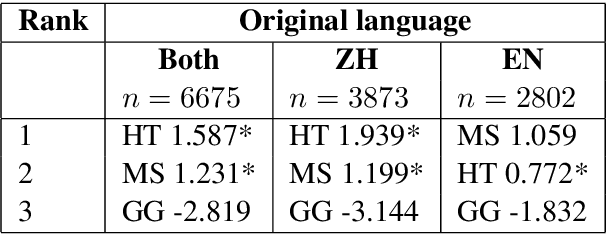

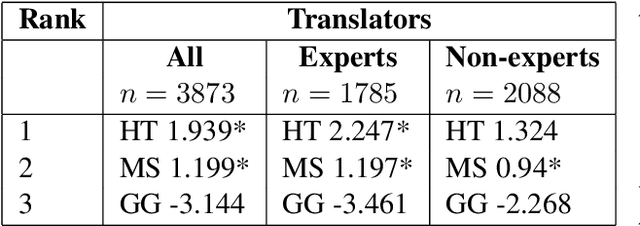
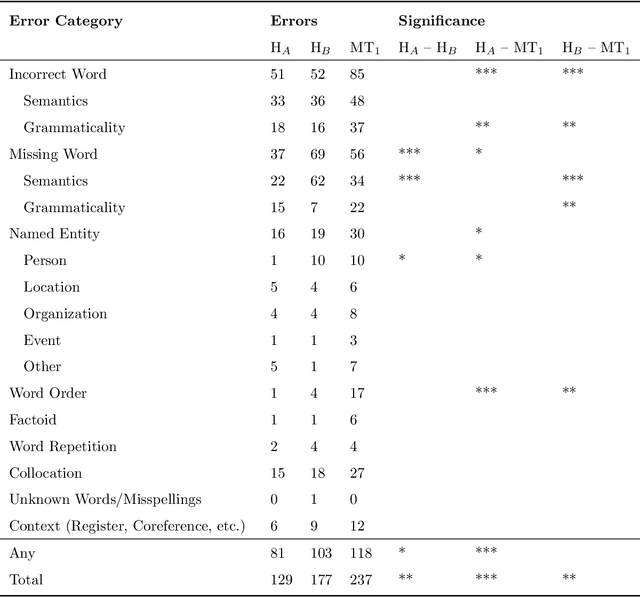
We reassess a recent study (Hassan et al., 2018) that claimed that machine translation (MT) has reached human parity for the translation of news from Chinese into English, using pairwise ranking and considering three variables that were not taken into account in that previous study: the language in which the source side of the test set was originally written, the translation proficiency of the evaluators, and the provision of inter-sentential context. If we consider only original source text (i.e. not translated from another language, or translationese), then we find evidence showing that human parity has not been achieved. We compare the judgments of professional translators against those of non-experts and discover that those of the experts result in higher inter-annotator agreement and better discrimination between human and machine translations. In addition, we analyse the human translations of the test set and identify important translation issues. Finally, based on these findings, we provide a set of recommendations for future human evaluations of MT.