 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparison of translation performance between DeepL and Supertext
Feb 04, 2025As strong machine translation (MT) systems are increasingly based on large language models (LLMs), reliable quality benchmarking requires methods that capture their ability to leverage extended context. This study compares two commercial MT systems -- DeepL and Supertext -- by assessing their performance on unsegmented texts. We evaluate translation quality across four language directions with professional translators assessing segments with full document-level context. While segment-level assessments indicate no strong preference between the systems in most cases, document-level analysis reveals a preference for Supertext in three out of four language directions, suggesting superior consistency across longer texts. We advocate for more context-sensitive evaluation methodologies to ensure that MT quality assessments reflect real-world usability. We release all evaluation data and scripts for further analysis and reproduction at https://github.com/supertext/evaluation_deepl_supertext.
A Methodology for Creating Question Answering Corpora Using Inverse Data Annotation
Apr 16, 2020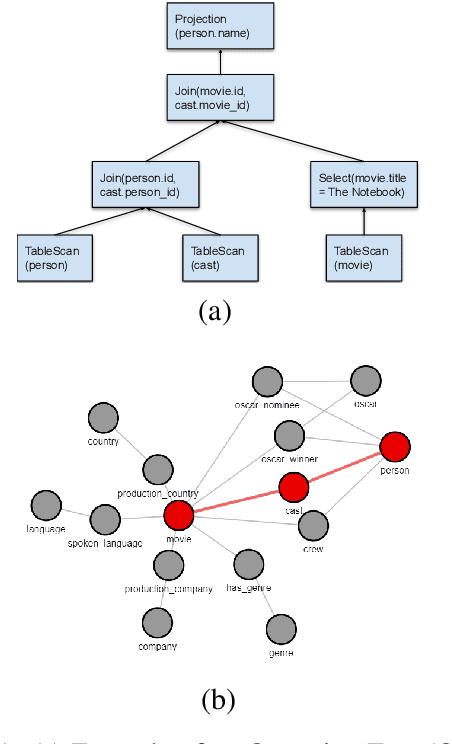



In this paper, we introduce a novel methodology to efficiently construct a corpus for question answering over structured data. For this, we introduce an intermediate representation that is based on the logical query plan in a database called Operation Trees (OT). This representation allows us to invert the annotation process without losing flexibility in the types of queries that we generate. Furthermore, it allows for fine-grained alignment of query tokens to OT operations. In our method, we randomly generate OTs from a context-free grammar. Afterwards, annotators have to write the appropriate natural language question that is represented by the OT. Finally, the annotators assign the tokens to the OT operations. We apply the method to create a new corpus OTTA (Operation Trees and Token Assignment), a large semantic parsing corpus for evaluating natural language interfaces to databases. We compare OTTA to Spider and LC-QuaD 2.0 and show that our methodology more than triples the annotation speed while maintaining the complexity of the queries. Finally, we train a state-of-the-art semantic parsing model on our data and show that our corpus is a challenging dataset and that the token alignment can be leveraged to increase the performance significantly.