 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError-preserving Automatic Speech Recognition of Young English Learners' Language
Jun 05, 2024



One of the central skills that language learners need to practice is speaking the language. Currently, students in school do not get enough speaking opportunities and lack conversational practice. Recent advances in speech technology and natural language processing allow for the creation of novel tools to practice their speaking skills. In this work, we tackle the first component of such a pipeline, namely, the automated speech recognition module (ASR), which faces a number of challenges: first, state-of-the-art ASR models are often trained on adult read-aloud data by native speakers and do not transfer well to young language learners' speech. Second, most ASR systems contain a powerful language model, which smooths out errors made by the speakers. To give corrective feedback, which is a crucial part of language learning, the ASR systems in our setting need to preserve the errors made by the language learners. In this work, we build an ASR system that satisfies these requirements: it works on spontaneous speech by young language learners and preserves their errors. For this, we collected a corpus containing around 85 hours of English audio spoken by learners in Switzerland from grades 4 to 6 on different language learning tasks, which we used to train an ASR model. Our experiments show that our model benefits from direct fine-tuning on children's voices and has a much higher error preservation rate than other models.
A Methodology for Creating Question Answering Corpora Using Inverse Data Annotation
Apr 16, 2020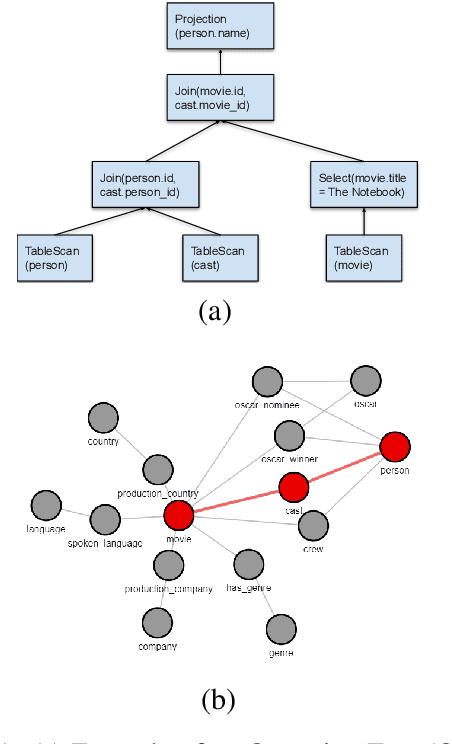



In this paper, we introduce a novel methodology to efficiently construct a corpus for question answering over structured data. For this, we introduce an intermediate representation that is based on the logical query plan in a database called Operation Trees (OT). This representation allows us to invert the annotation process without losing flexibility in the types of queries that we generate. Furthermore, it allows for fine-grained alignment of query tokens to OT operations. In our method, we randomly generate OTs from a context-free grammar. Afterwards, annotators have to write the appropriate natural language question that is represented by the OT. Finally, the annotators assign the tokens to the OT operations. We apply the method to create a new corpus OTTA (Operation Trees and Token Assignment), a large semantic parsing corpus for evaluating natural language interfaces to databases. We compare OTTA to Spider and LC-QuaD 2.0 and show that our methodology more than triples the annotation speed while maintaining the complexity of the queries. Finally, we train a state-of-the-art semantic parsing model on our data and show that our corpus is a challenging dataset and that the token alignment can be leveraged to increase the performance significantly.