 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the TalentCLEF 2025: Skill and Job Title Intelligence for Human Capital Management
Jul 17, 2025Advances in natural language processing and large language models are driving a major transformation in Human Capital Management, with a growing interest in building smart systems based on language technologies for talent acquisition, upskilling strategies, and workforce planning. However, the adoption and progress of these technologies critically depend on the development of reliable and fair models, properly evaluated on public data and open benchmarks, which have so far been unavailable in this domain. To address this gap, we present TalentCLEF 2025, the first evaluation campaign focused on skill and job title intelligence. The lab consists of two tasks: Task A - Multilingual Job Title Matching, covering English, Spanish, German, and Chinese; and Task B - Job Title-Based Skill Prediction, in English. Both corpora were built from real job applications, carefully anonymized, and manually annotated to reflect the complexity and diversity of real-world labor market data, including linguistic variability and gender-marked expressions. The evaluations included monolingual and cross-lingual scenarios and covered the evaluation of gender bias. TalentCLEF attracted 76 registered teams with more than 280 submissions. Most systems relied on information retrieval techniques built with multilingual encoder-based models fine-tuned with contrastive learning, and several of them incorporated large language models for data augmentation or re-ranking. The results show that the training strategies have a larger effect than the size of the model alone. TalentCLEF provides the first public benchmark in this field and encourages the development of robust, fair, and transferable language technologies for the labor market.
ViClaim: A Multilingual Multilabel Dataset for Automatic Claim Detection in Videos
Apr 17, 2025The growing influence of video content as a medium for communication and misinformation underscores the urgent need for effective tools to analyze claims in multilingual and multi-topic settings. Existing efforts in misinformation detection largely focus on written text, leaving a significant gap in addressing the complexity of spoken text in video transcripts. We introduce ViClaim, a dataset of 1,798 annotated video transcripts across three languages (English, German, Spanish) and six topics. Each sentence in the transcripts is labeled with three claim-related categories: fact-check-worthy, fact-non-check-worthy, or opinion. We developed a custom annotation tool to facilitate the highly complex annotation process. Experiments with state-of-the-art multilingual language models demonstrate strong performance in cross-validation (macro F1 up to 0.896) but reveal challenges in generalization to unseen topics, particularly for distinct domains. Our findings highlight the complexity of claim detection in video transcripts. ViClaim offers a robust foundation for advancing misinformation detection in video-based communication, addressing a critical gap in multimodal analysis.
Spot The Bot: A Robust and Efficient Framework for the Evaluation of Conversational Dialogue Systems
Oct 05, 2020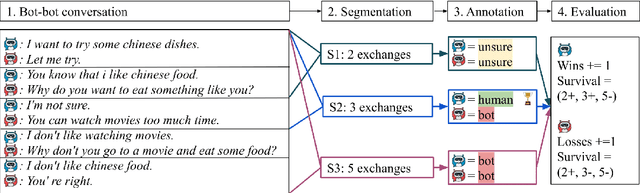
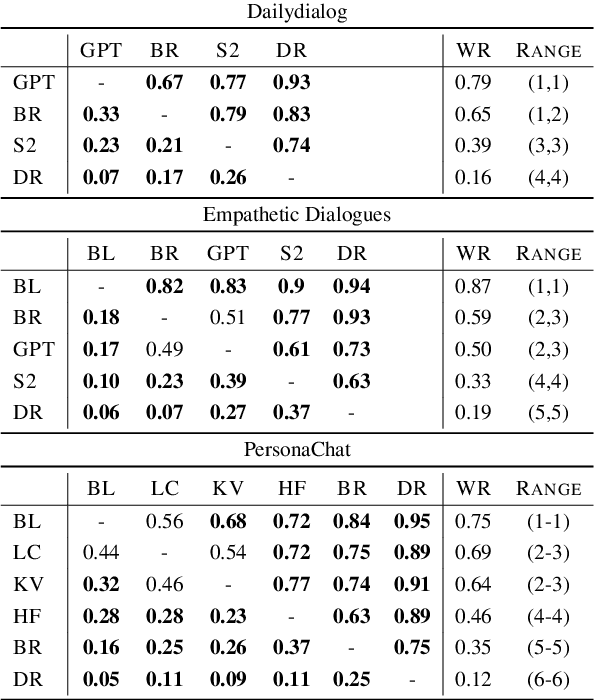
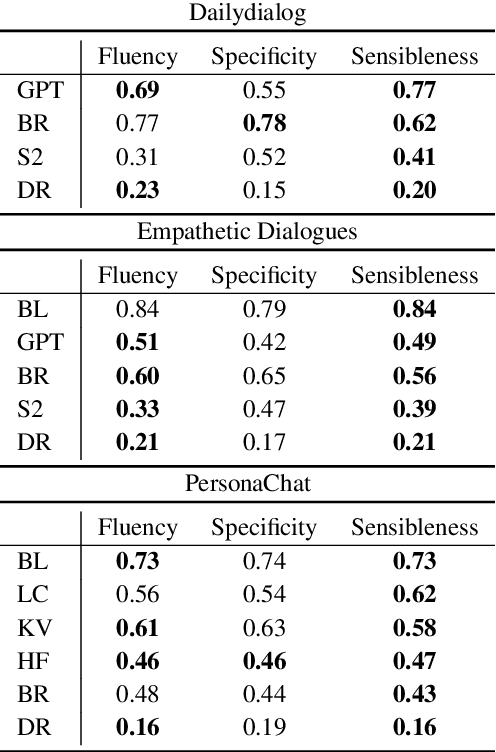
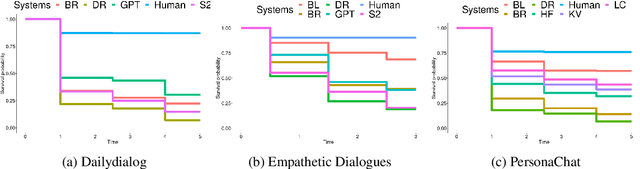
The lack of time-efficient and reliable evaluation methods hamper the development of conversational dialogue systems (chatbots). Evaluations requiring humans to converse with chatbots are time and cost-intensive, put high cognitive demands on the human judges, and yield low-quality results. In this work, we introduce \emph{Spot The Bot}, a cost-efficient and robust evaluation framework that replaces human-bot conversations with conversations between bots. Human judges then only annotate for each entity in a conversation whether they think it is human or not (assuming there are humans participants in these conversations). These annotations then allow us to rank chatbots regarding their ability to mimic the conversational behavior of humans. Since we expect that all bots are eventually recognized as such, we incorporate a metric that measures which chatbot can uphold human-like behavior the longest, i.e., \emph{Survival Analysis}. This metric has the ability to correlate a bot's performance to certain of its characteristics (e.g., \ fluency or sensibleness), yielding interpretable results. The comparably low cost of our framework allows for frequent evaluations of chatbots during their evaluation cycle. We empirically validate our claims by applying \emph{Spot The Bot} to three domains, evaluating several state-of-the-art chatbots, and drawing comparisons to related work. The framework is released as a ready-to-use tool.
A Methodology for Creating Question Answering Corpora Using Inverse Data Annotation
Apr 16, 2020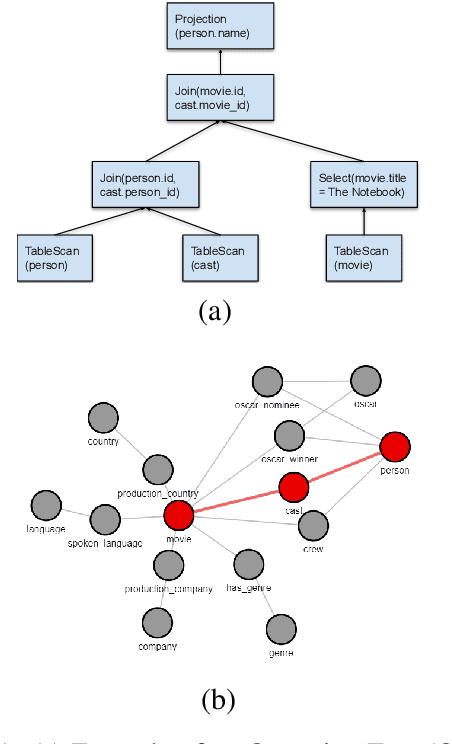



In this paper, we introduce a novel methodology to efficiently construct a corpus for question answering over structured data. For this, we introduce an intermediate representation that is based on the logical query plan in a database called Operation Trees (OT). This representation allows us to invert the annotation process without losing flexibility in the types of queries that we generate. Furthermore, it allows for fine-grained alignment of query tokens to OT operations. In our method, we randomly generate OTs from a context-free grammar. Afterwards, annotators have to write the appropriate natural language question that is represented by the OT. Finally, the annotators assign the tokens to the OT operations. We apply the method to create a new corpus OTTA (Operation Trees and Token Assignment), a large semantic parsing corpus for evaluating natural language interfaces to databases. We compare OTTA to Spider and LC-QuaD 2.0 and show that our methodology more than triples the annotation speed while maintaining the complexity of the queries. Finally, we train a state-of-the-art semantic parsing model on our data and show that our corpus is a challenging dataset and that the token alignment can be leveraged to increase the performance significantly.
Survey on Evaluation Methods for Dialogue Systems
May 10, 2019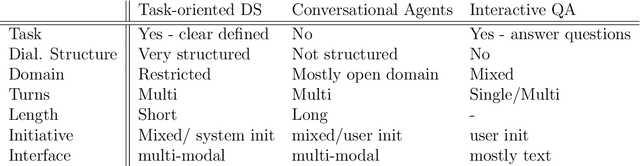
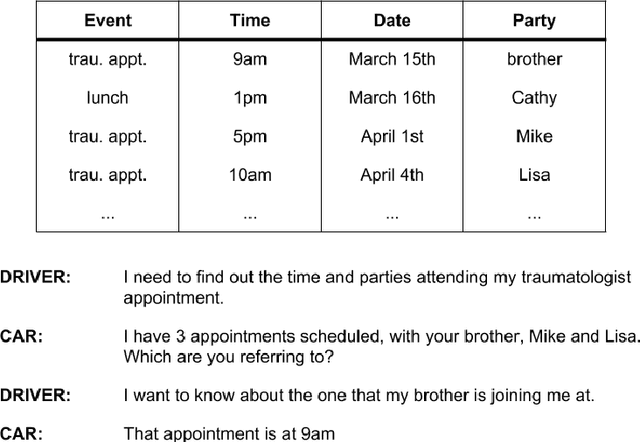

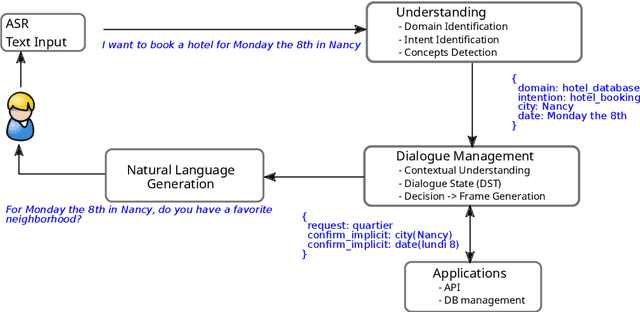
In this paper we survey the methods and concepts developed for the evaluation of dialogue systems. Evaluation is a crucial part during the development process. Often, dialogue systems are evaluated by means of human evaluations and questionnaires. However, this tends to be very cost and time intensive. Thus, much work has been put into finding methods, which allow to reduce the involvement of human labour. In this survey, we present the main concepts and methods. For this, we differentiate between the various classes of dialogue systems (task-oriented dialogue systems, conversational dialogue systems, and question-answering dialogue systems). We cover each class by introducing the main technologies developed for the dialogue systems and then by presenting the evaluation methods regarding this class.