 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViClaim: A Multilingual Multilabel Dataset for Automatic Claim Detection in Videos
Apr 17, 2025The growing influence of video content as a medium for communication and misinformation underscores the urgent need for effective tools to analyze claims in multilingual and multi-topic settings. Existing efforts in misinformation detection largely focus on written text, leaving a significant gap in addressing the complexity of spoken text in video transcripts. We introduce ViClaim, a dataset of 1,798 annotated video transcripts across three languages (English, German, Spanish) and six topics. Each sentence in the transcripts is labeled with three claim-related categories: fact-check-worthy, fact-non-check-worthy, or opinion. We developed a custom annotation tool to facilitate the highly complex annotation process. Experiments with state-of-the-art multilingual language models demonstrate strong performance in cross-validation (macro F1 up to 0.896) but reveal challenges in generalization to unseen topics, particularly for distinct domains. Our findings highlight the complexity of claim detection in video transcripts. ViClaim offers a robust foundation for advancing misinformation detection in video-based communication, addressing a critical gap in multimodal analysis.
A Measure of the System Dependence of Automated Metrics
Dec 04, 2024



Automated metrics for Machine Translation have made significant progress, with the goal of replacing expensive and time-consuming human evaluations. These metrics are typically assessed by their correlation with human judgments, which captures the monotonic relationship between human and metric scores. However, we argue that it is equally important to ensure that metrics treat all systems fairly and consistently. In this paper, we introduce a method to evaluate this aspect.
Favi-Score: A Measure for Favoritism in Automated Preference Ratings for Generative AI Evaluation
Jun 03, 2024



Generative AI systems have become ubiquitous for all kinds of modalities, which makes the issue of the evaluation of such models more pressing. One popular approach is preference ratings, where the generated outputs of different systems are shown to evaluators who choose their preferences. In recent years the field shifted towards the development of automated (trained) metrics to assess generated outputs, which can be used to create preference ratings automatically. In this work, we investigate the evaluation of the metrics themselves, which currently rely on measuring the correlation to human judgments or computing sign accuracy scores. These measures only assess how well the metric agrees with the human ratings. However, our research shows that this does not tell the whole story. Most metrics exhibit a disagreement with human system assessments which is often skewed in favor of particular text generation systems, exposing a degree of favoritism in automated metrics. This paper introduces a formal definition of favoritism in preference metrics, and derives the Favi-Score, which measures this phenomenon. In particular we show that favoritism is strongly related to errors in final system rankings. Thus, we propose that preference-based metrics ought to be evaluated on both sign accuracy scores and favoritism.
Correction of Errors in Preference Ratings from Automated Metrics for Text Generation
Jun 06, 2023



A major challenge in the field of Text Generation is evaluation: Human evaluations are cost-intensive, and automated metrics often display considerable disagreement with human judgments. In this paper, we propose a statistical model of Text Generation evaluation that accounts for the error-proneness of automated metrics when used to generate preference rankings between system outputs. We show that existing automated metrics are generally over-confident in assigning significant differences between systems in this setting. However, our model enables an efficient combination of human and automated ratings to remedy the error-proneness of the automated metrics. We show that using this combination, we only require about 50% of the human annotations typically used in evaluations to arrive at robust and statistically significant results while yielding the same evaluation outcome as the pure human evaluation in 95% of cases. We showcase the benefits of approach for three text generation tasks: dialogue systems, machine translation, and text summarization.
On the Effectiveness of Automated Metrics for Text Generation Systems
Oct 24, 2022



A major challenge in the field of Text Generation is evaluation because we lack a sound theory that can be leveraged to extract guidelines for evaluation campaigns. In this work, we propose a first step towards such a theory that incorporates different sources of uncertainty, such as imperfect automated metrics and insufficiently sized test sets. The theory has practical applications, such as determining the number of samples needed to reliably distinguish the performance of a set of Text Generation systems in a given setting. We showcase the application of the theory on the WMT 21 and Spot-The-Bot evaluation data and outline how it can be leveraged to improve the evaluation protocol regarding the reliability, robustness, and significance of the evaluation outcome.
Probing the Robustness of Trained Metrics for Conversational Dialogue Systems
Feb 28, 2022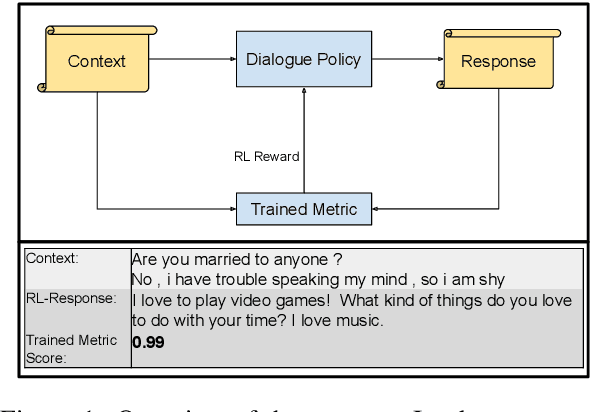

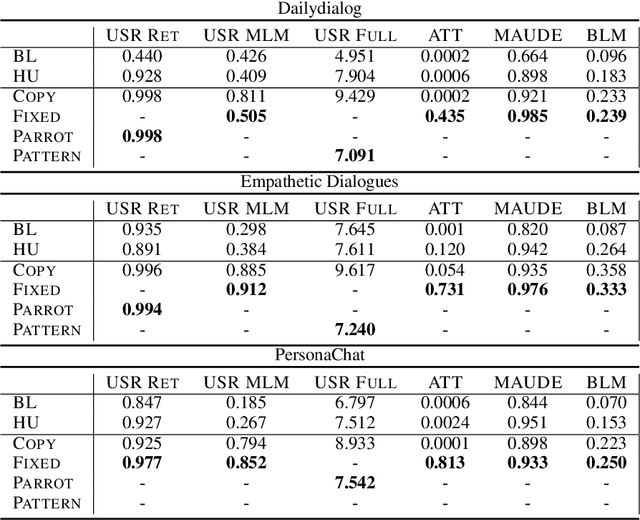
This paper introduces an adversarial method to stress-test trained metrics to evaluate conversational dialogue systems. The method leverages Reinforcement Learning to find response strategies that elicit optimal scores from the trained metrics. We apply our method to test recently proposed trained metrics. We find that they all are susceptible to giving high scores to responses generated by relatively simple and obviously flawed strategies that our method converges on. For instance, simply copying parts of the conversation context to form a response yields competitive scores or even outperforms responses written by humans.
Spot The Bot: A Robust and Efficient Framework for the Evaluation of Conversational Dialogue Systems
Oct 05, 2020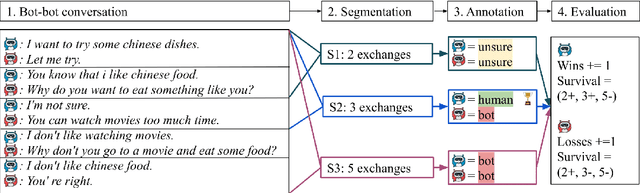
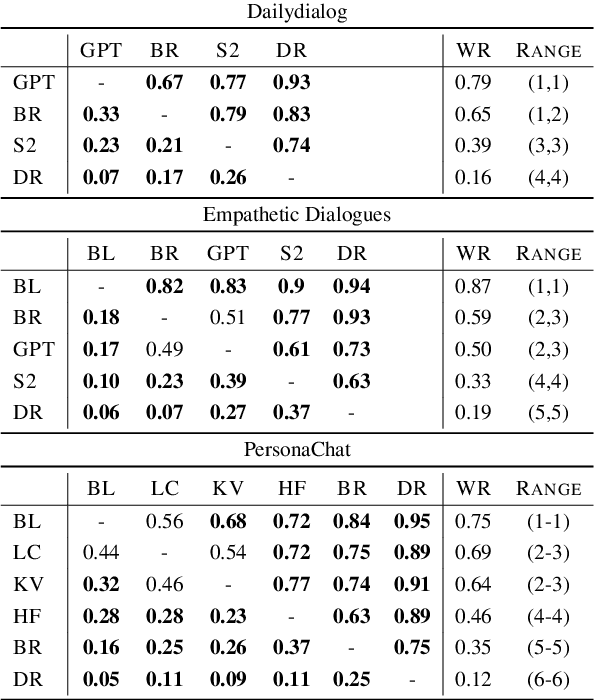
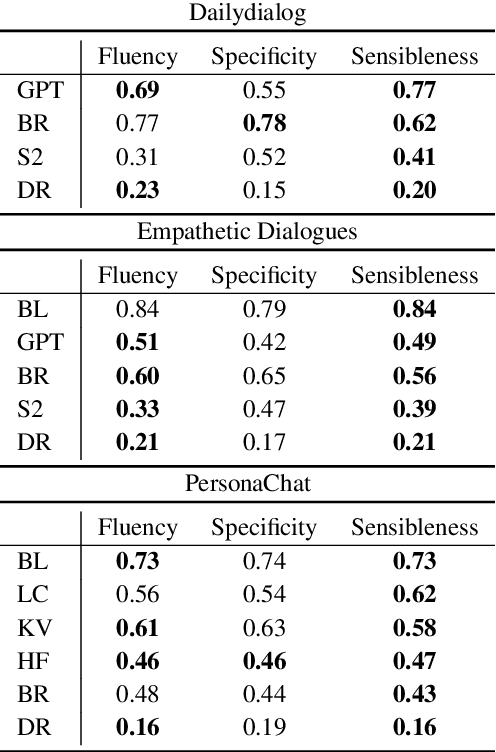
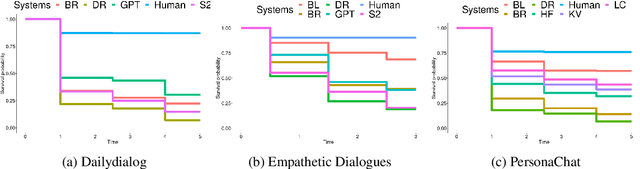
The lack of time-efficient and reliable evaluation methods hamper the development of conversational dialogue systems (chatbots). Evaluations requiring humans to converse with chatbots are time and cost-intensive, put high cognitive demands on the human judges, and yield low-quality results. In this work, we introduce \emph{Spot The Bot}, a cost-efficient and robust evaluation framework that replaces human-bot conversations with conversations between bots. Human judges then only annotate for each entity in a conversation whether they think it is human or not (assuming there are humans participants in these conversations). These annotations then allow us to rank chatbots regarding their ability to mimic the conversational behavior of humans. Since we expect that all bots are eventually recognized as such, we incorporate a metric that measures which chatbot can uphold human-like behavior the longest, i.e., \emph{Survival Analysis}. This metric has the ability to correlate a bot's performance to certain of its characteristics (e.g., \ fluency or sensibleness), yielding interpretable results. The comparably low cost of our framework allows for frequent evaluations of chatbots during their evaluation cycle. We empirically validate our claims by applying \emph{Spot The Bot} to three domains, evaluating several state-of-the-art chatbots, and drawing comparisons to related work. The framework is released as a ready-to-use tool.