 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Conversational Question Answering Systems after Deployment using Feedback-Weighted Learning
Nov 01, 2020
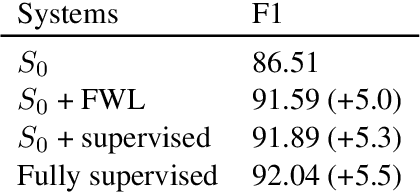

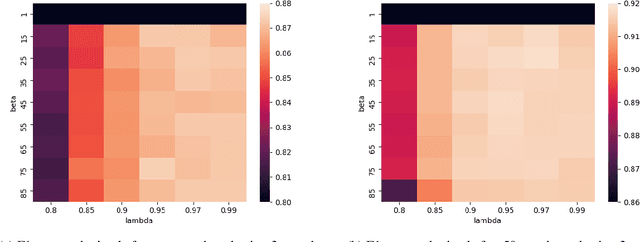
The interaction of conversational systems with users poses an exciting opportunity for improving them after deployment, but little evidence has been provided of its feasibility. In most applications, users are not able to provide the correct answer to the system, but they are able to provide binary (correct, incorrect) feedback. In this paper we propose feedback-weighted learning based on importance sampling to improve upon an initial supervised system using binary user feedback. We perform simulated experiments on document classification (for development) and Conversational Question Answering datasets like QuAC and DoQA, where binary user feedback is derived from gold annotations. The results show that our method is able to improve over the initial supervised system, getting close to a fully-supervised system that has access to the same labeled examples in in-domain experiments (QuAC), and even matching in out-of-domain experiments (DoQA). Our work opens the prospect to exploit interactions with real users and improve conversational systems after deployment.
DoQA -- Accessing Domain-Specific FAQs via Conversational QA
May 18, 2020

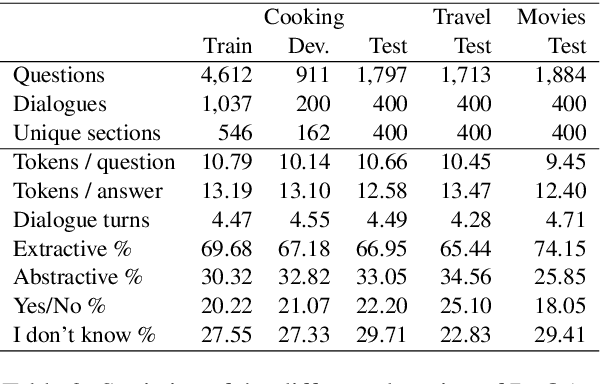
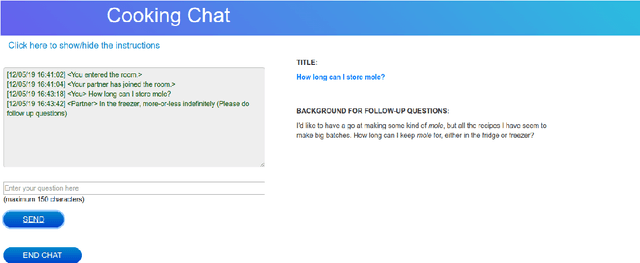
The goal of this work is to build conversational Question Answering (QA) interfaces for the large body of domain-specific information available in FAQ sites. We present DoQA, a dataset with 2,437 dialogues and 10,917 QA pairs. The dialogues are collected from three Stack Exchange sites using the Wizard of Oz method with crowdsourcing. Compared to previous work, DoQA comprises well-defined information needs, leading to more coherent and natural conversations with less factoid questions and is multi-domain. In addition, we introduce a more realistic information retrieval(IR) scenario where the system needs to find the answer in any of the FAQ documents. The results of an existing, strong, system show that, thanks to transfer learning from a Wikipedia QA dataset and fine tuning on a single FAQ domain, it is possible to build high quality conversational QA systems for FAQs without in-domain training data. The good results carry over into the more challenging IR scenario. In both cases, there is still ample room for improvement, as indicated by the higher human upperbound.
Survey on Evaluation Methods for Dialogue Systems
May 10, 2019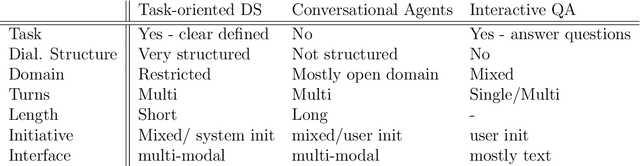

In this paper we survey the methods and concepts developed for the evaluation of dialogue systems. Evaluation is a crucial part during the development process. Often, dialogue systems are evaluated by means of human evaluations and questionnaires. However, this tends to be very cost and time intensive. Thus, much work has been put into finding methods, which allow to reduce the involvement of human labour. In this survey, we present the main concepts and methods. For this, we differentiate between the various classes of dialogue systems (task-oriented dialogue systems, conversational dialogue systems, and question-answering dialogue systems). We cover each class by introducing the main technologies developed for the dialogue systems and then by presenting the evaluation methods regarding this class.
Proceedings of the LexSem+Logics Workshop 2016
Aug 14, 2016Lexical semantics continues to play an important role in driving research directions in NLP, with the recognition and understanding of context becoming increasingly important in delivering successful outcomes in NLP tasks. Besides traditional processing areas such as word sense and named entity disambiguation, the creation and maintenance of dictionaries, annotated corpora and resources have become cornerstones of lexical semantics research and produced a wealth of contextual information that NLP processes can exploit. New efforts both to link and construct from scratch such information - as Linked Open Data or by way of formal tools coming from logic, ontologies and automated reasoning - have increased the interoperability and accessibility of resources for lexical and computational semantics, even in those languages for which they have previously been limited. LexSem+Logics 2016 combines the 1st Workshop on Lexical Semantics for Lesser-Resources Languages and the 3rd Workshop on Logics and Ontologies. The accepted papers in our program covered topics across these two areas, including: the encoding of plurals in Wordnets, the creation of a thesaurus from multiple sources based on semantic similarity metrics, and the use of cross-lingual treebanks and annotations for universal part-of-speech tagging. We also welcomed talks from two distinguished speakers: on Portuguese lexical knowledge bases (different approaches, results and their application in NLP tasks) and on new strategies for open information extraction (the capture of verb-based propositions from massive text corpora).