 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Cues in Machine Translation: Investigating the Potential of Multi-Source Input Strategies in LLMs and NMT Systems
Mar 10, 2025



We explore the impact of multi-source input strategies on machine translation (MT) quality, comparing GPT-4o, a large language model (LLM), with a traditional multilingual neural machine translation (NMT) system. Using intermediate language translations as contextual cues, we evaluate their effectiveness in enhancing English and Chinese translations into Portuguese. Results suggest that contextual information significantly improves translation quality for domain-specific datasets and potentially for linguistically distant language pairs, with diminishing returns observed in benchmarks with high linguistic variability. Additionally, we demonstrate that shallow fusion, a multi-source approach we apply within the NMT system, shows improved results when using high-resource languages as context for other translation pairs, highlighting the importance of strategic context language selection.
Neural Machine Translation Models Can Learn to be Few-shot Learners
Sep 15, 2023



The emergent ability of Large Language Models to use a small number of examples to learn to perform in novel domains and tasks, also called in-context learning (ICL). In this work, we show that a much smaller model can be trained to perform ICL by fine-tuning towards a specialized training objective, exemplified on the task of domain adaptation for neural machine translation. With this capacity for ICL, the model can take advantage of relevant few-shot examples to adapt its output towards the domain. We compare the quality of this domain adaptation to traditional supervised techniques and ICL with a 40B-parameter Large Language Model. Our approach allows efficient batch inference on a mix of domains and outperforms state-of-the-art baselines in terms of both translation quality and immediate adaptation rate, i.e. the ability to reproduce a specific term after being shown a single example.
The Impact of Text Presentation on Translator Performance
Nov 11, 2020

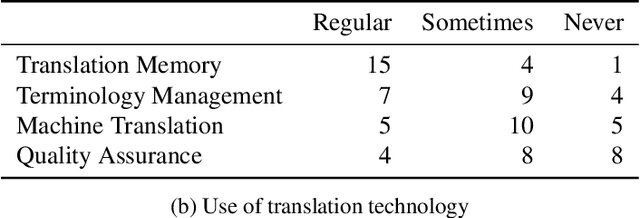
Widely used computer-aided translation (CAT) tools divide documents into segments such as sentences and arrange them in a side-by-side, spreadsheet-like view. We present the first controlled evaluation of these design choices on translator performance, measuring speed and accuracy in three experimental text processing tasks. We find significant evidence that sentence-by-sentence presentation enables faster text reproduction and within-sentence error identification compared to unsegmented text, and that a top-and-bottom arrangement of source and target sentences enables faster text reproduction compared to a side-by-side arrangement. For revision, on the other hand, our results suggest that presenting unsegmented text results in the highest accuracy and time efficiency. Our findings have direct implications for best practices in designing CAT tools.
Compact Personalized Models for Neural Machine Translation
Nov 05, 2018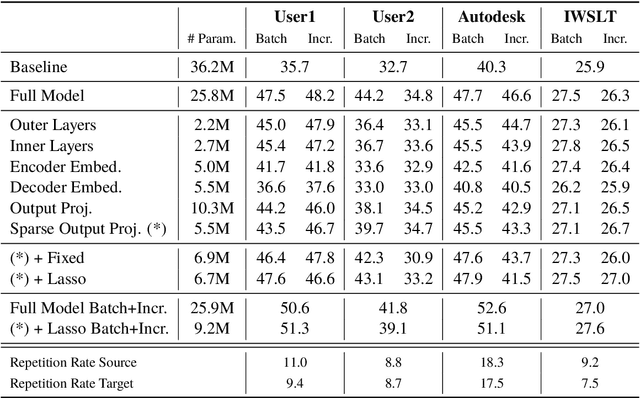

We propose and compare methods for gradient-based domain adaptation of self-attentive neural machine translation models. We demonstrate that a large proportion of model parameters can be frozen during adaptation with minimal or no reduction in translation quality by encouraging structured sparsity in the set of offset tensors during learning via group lasso regularization. We evaluate this technique for both batch and incremental adaptation across multiple data sets and language pairs. Our system architecture - combining a state-of-the-art self-attentive model with compact domain adaptation - provides high quality personalized machine translation that is both space and time efficient.
A User-Study on Online Adaptation of Neural Machine Translation to Human Post-Edits
Sep 18, 2018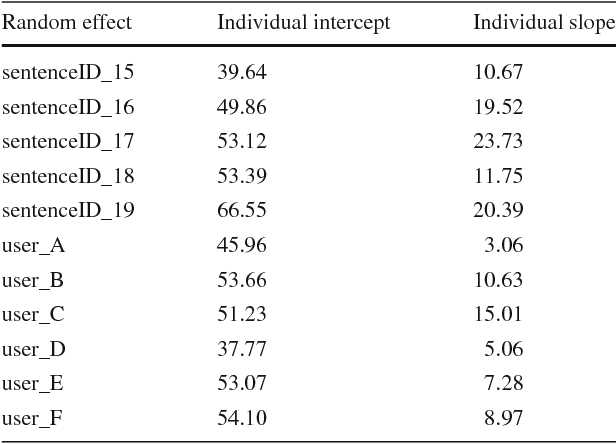


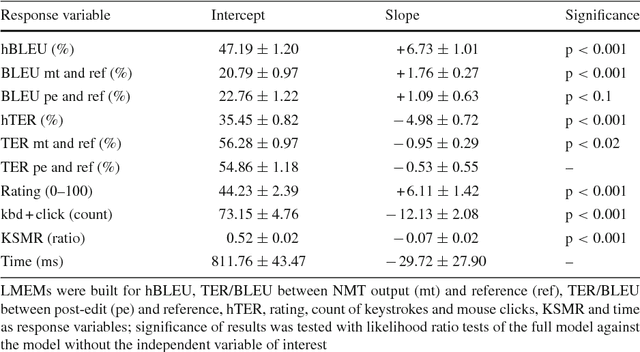
The advantages of neural machine translation (NMT) have been extensively validated for offline translation of several language pairs for different domains of spoken and written language. However, research on interactive learning of NMT by adaptation to human post-edits has so far been confined to simulation experiments. We present the first user study on online adaptation of NMT to user post-edits in the domain of patent translation. Our study involves 29 human subjects (translation students) whose post-editing effort and translation quality were measured on about 4,500 interactions of a human post-editor and a machine translation system integrating an online adaptive learning algorithm. Our experimental results show a significant reduction of human post-editing effort due to online adaptation in NMT according to several evaluation metrics, including hTER, hBLEU, and KSMR. Furthermore, we found significant improvements in BLEU/TER between NMT outputs and professional translations in granted patents, providing further evidence for the advantages of online adaptive NMT in an interactive setup.