 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation Models Can Learn to be Few-shot Learners
Sep 15, 2023



The emergent ability of Large Language Models to use a small number of examples to learn to perform in novel domains and tasks, also called in-context learning (ICL). In this work, we show that a much smaller model can be trained to perform ICL by fine-tuning towards a specialized training objective, exemplified on the task of domain adaptation for neural machine translation. With this capacity for ICL, the model can take advantage of relevant few-shot examples to adapt its output towards the domain. We compare the quality of this domain adaptation to traditional supervised techniques and ICL with a 40B-parameter Large Language Model. Our approach allows efficient batch inference on a mix of domains and outperforms state-of-the-art baselines in terms of both translation quality and immediate adaptation rate, i.e. the ability to reproduce a specific term after being shown a single example.
STAR: A Schema-Guided Dialog Dataset for Transfer Learning
Oct 22, 2020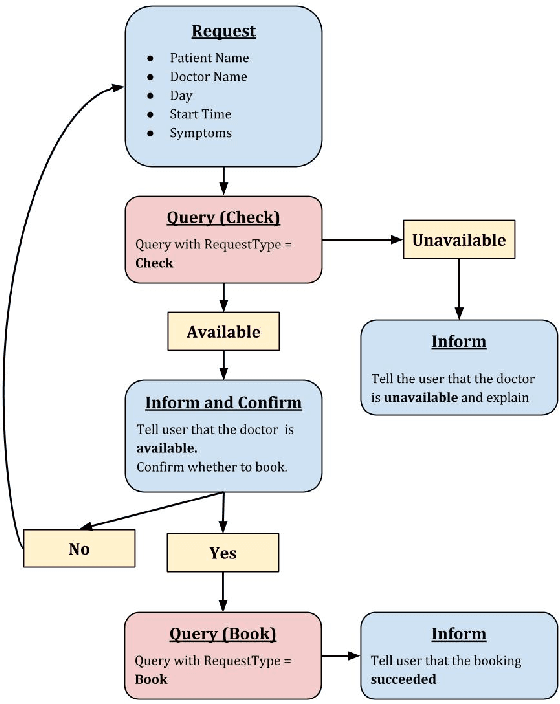
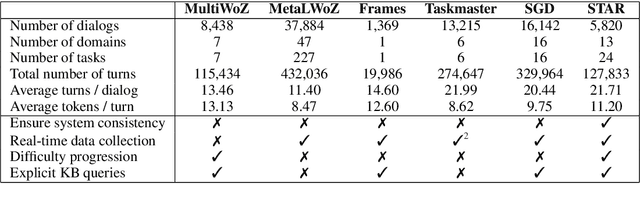
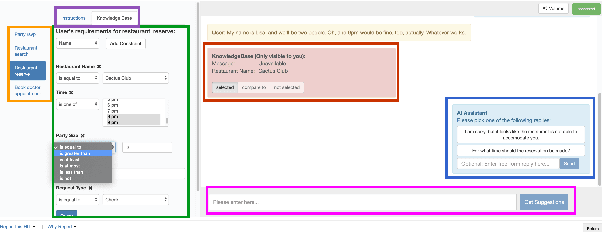
We present STAR, a schema-guided task-oriented dialog dataset consisting of 127,833 utterances and knowledge base queries across 5,820 task-oriented dialogs in 13 domains that is especially designed to facilitate task and domain transfer learning in task-oriented dialog. Furthermore, we propose a scalable crowd-sourcing paradigm to collect arbitrarily large datasets of the same quality as STAR. Moreover, we introduce novel schema-guided dialog models that use an explicit description of the task(s) to generalize from known to unknown tasks. We demonstrate the effectiveness of these models, particularly for zero-shot generalization across tasks and domains.
Where is the context? -- A critique of recent dialogue datasets
Apr 22, 2020

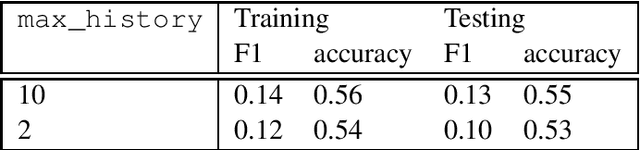
Recent dialogue datasets like MultiWOZ 2.1 and Taskmaster-1 constitute some of the most challenging tasks for present-day dialogue models and, therefore, are widely used for system evaluation. We identify several issues with the above-mentioned datasets, such as history independence, strong knowledge base dependence, and ambiguous system responses. Finally, we outline key desiderata for future datasets that we believe would be more suitable for the construction of conversational artificial intelligence.
Dialogue Transformers
Oct 01, 2019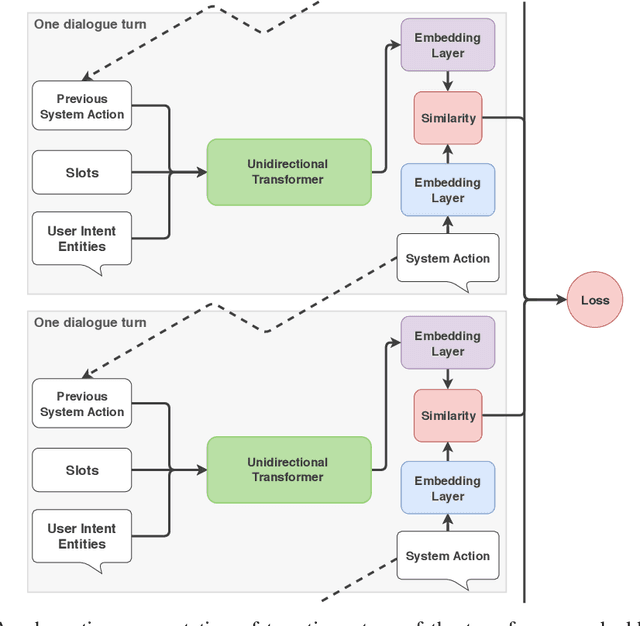


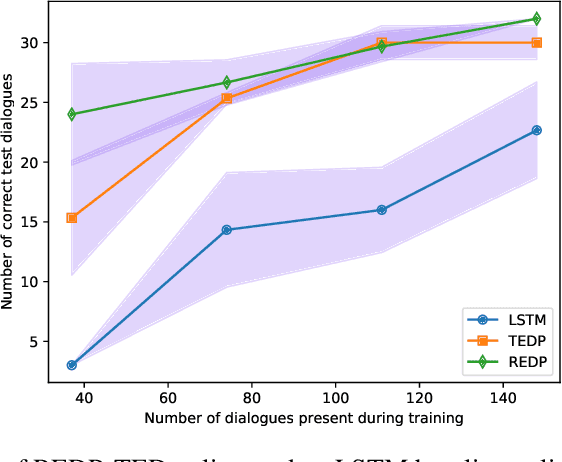
We introduce a dialogue policy based on a transformer architecture, where the self-attention mechanism operates over the sequence of dialogue turns. Recent work has used hierarchical recurrent neural networks to encode multiple utterances in a dialogue context, but we argue that a pure self-attention mechanism is more suitable. By default, an RNN assumes that every item in a sequence is relevant for producing an encoding of the full sequence, but a single conversation can consist of multiple overlapping discourse segments as speakers interleave multiple topics. A transformer picks which turns to include in its encoding of the current dialogue state, and is naturally suited to selectively ignoring or attending to dialogue history. We compare the performance of the Transformer Embedding Dialogue (TED) policy to an LSTM and to the REDP, which was specifically designed to overcome this limitation of RNNs. We show that the TED policy's behaviour compares favourably, both in terms of accuracy and speed.