 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Human-Preference Alignment for Neural Machine Translation with Direct Quality Optimization
Sep 26, 2024


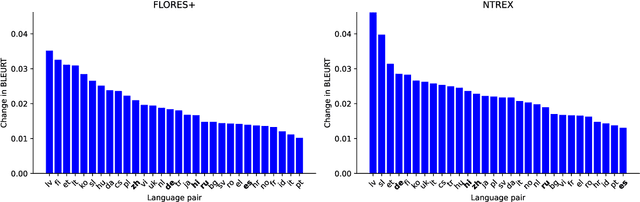
Reinforcement Learning from Human Feedback (RLHF) and derivative techniques like Direct Preference Optimization (DPO) are task-alignment algorithms used to repurpose general, foundational models for specific tasks. We show that applying task-alignment to neural machine translation (NMT) addresses an existing task--data mismatch in NMT, leading to improvements across all languages of a multilingual model, even when task-alignment is only applied to a subset of those languages. We do so by introducing Direct Quality Optimization (DQO), a variant of DPO leveraging a pre-trained translation quality estimation model as a proxy for human preferences, and verify the improvements with both automatic metrics and human evaluation.
Neural Machine Translation Models Can Learn to be Few-shot Learners
Sep 15, 2023



The emergent ability of Large Language Models to use a small number of examples to learn to perform in novel domains and tasks, also called in-context learning (ICL). In this work, we show that a much smaller model can be trained to perform ICL by fine-tuning towards a specialized training objective, exemplified on the task of domain adaptation for neural machine translation. With this capacity for ICL, the model can take advantage of relevant few-shot examples to adapt its output towards the domain. We compare the quality of this domain adaptation to traditional supervised techniques and ICL with a 40B-parameter Large Language Model. Our approach allows efficient batch inference on a mix of domains and outperforms state-of-the-art baselines in terms of both translation quality and immediate adaptation rate, i.e. the ability to reproduce a specific term after being shown a single example.
Early Warning Signals of Social Instabilities in Twitter Data
Mar 03, 2023
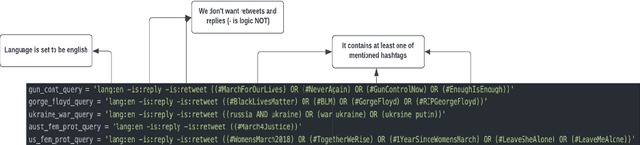


The goal of this project is to create and study novel techniques to identify early warning signals for socially disruptive events, like riots, wars, or revolutions using only publicly available data on social media. Such techniques need to be robust enough to work on real-time data: to achieve this goal we propose a topological approach together with more standard BERT models. Indeed, topology-based algorithms, being provably stable against deformations and noise, seem to work well in low-data regimes. The general idea is to build a binary classifier that predicts if a given tweet is related to a disruptive event or not. The results indicate that the persistent-gradient approach is stable and even more performant than deep-learning-based anomaly detection algorithms. We also benchmark the generalisability of the methodology against out-of-samples tasks, with very promising results.
The Topological BERT: Transforming Attention into Topology for Natural Language Processing
Jun 30, 2022



In recent years, the introduction of the Transformer models sparked a revolution in natural language processing (NLP). BERT was one of the first text encoders using only the attention mechanism without any recurrent parts to achieve state-of-the-art results on many NLP tasks. This paper introduces a text classifier using topological data analysis. We use BERT's attention maps transformed into attention graphs as the only input to that classifier. The model can solve tasks such as distinguishing spam from ham messages, recognizing whether a sentence is grammatically correct, or evaluating a movie review as negative or positive. It performs comparably to the BERT baseline and outperforms it on some tasks. Additionally, we propose a new method to reduce the number of BERT's attention heads considered by the topological classifier, which allows us to prune the number of heads from 144 down to as few as ten with no reduction in performance. Our work also shows that the topological model displays higher robustness against adversarial attacks than the original BERT model, which is maintained during the pruning process. To the best of our knowledge, this work is the first to confront topological-based models with adversarial attacks in the context of NLP.
Persformer: A Transformer Architecture for Topological Machine Learning
Dec 30, 2021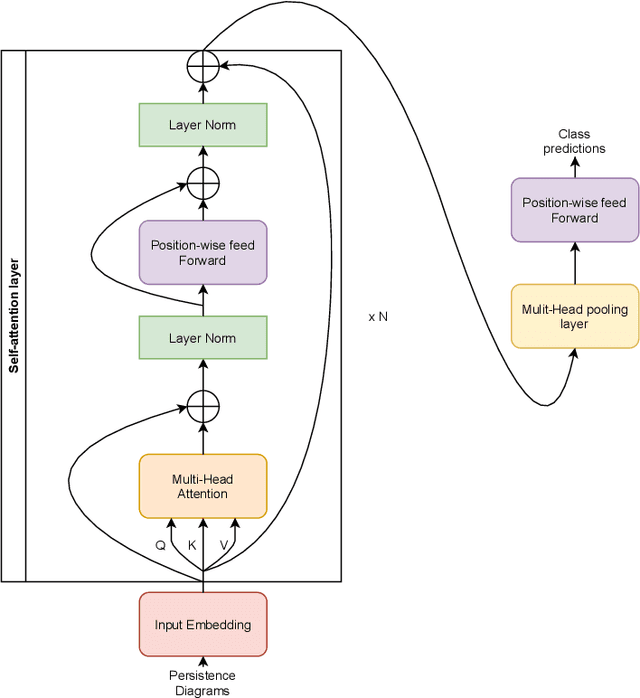
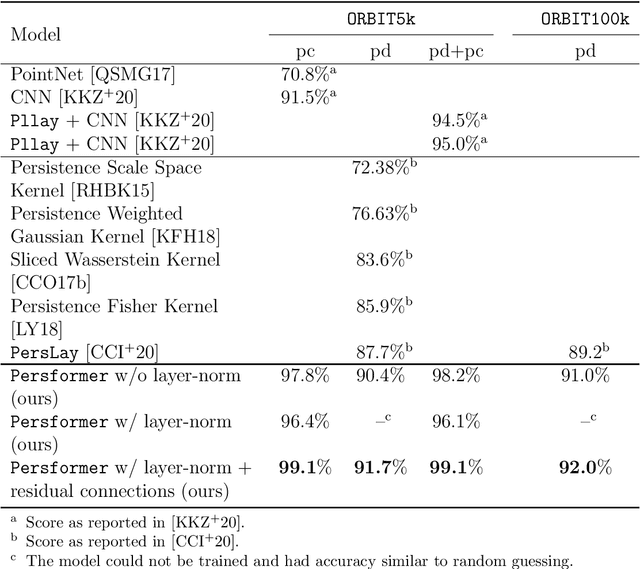


One of the main challenges of Topological Data Analysis (TDA) is to extract features from persistent diagrams directly usable by machine learning algorithms. Indeed, persistence diagrams are intrinsically (multi-)sets of points in R2 and cannot be seen in a straightforward manner as vectors. In this article, we introduce Persformer, the first Transformer neural network architecture that accepts persistence diagrams as input. The Persformer architecture significantly outperforms previous topological neural network architectures on classical synthetic benchmark datasets. Moreover, it satisfies a universal approximation theorem. This allows us to introduce the first interpretability method for topological machine learning, which we explore in two examples.