 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Dialogue with In-Context Learning
Feb 19, 2024


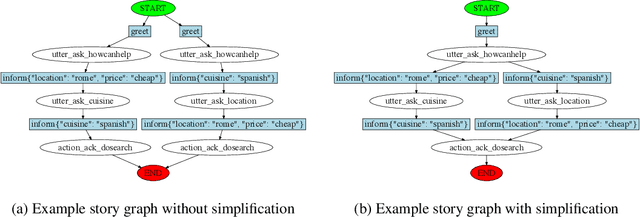
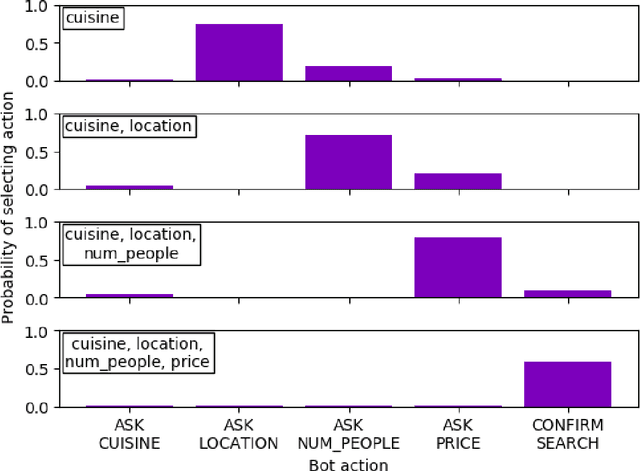
We describe a system for building task-oriented dialogue systems combining the in-context learning abilities of large language models (LLMs) with the deterministic execution of business logic. LLMs are used to translate between the surface form of the conversation and a domain-specific language (DSL) which is used to progress the business logic. We compare our approach to the intent-based NLU approach predominantly used in industry today. Our experiments show that developing chatbots with our system requires significantly less effort than established approaches, that these chatbots can successfully navigate complex dialogues which are extremely challenging for NLU-based systems, and that our system has desirable properties for scaling task-oriented dialogue systems to a large number of tasks. We make our implementation available for use and further study.
DIET: Lightweight Language Understanding for Dialogue Systems
May 11, 2020
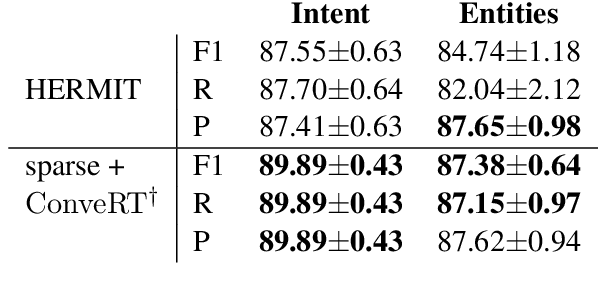

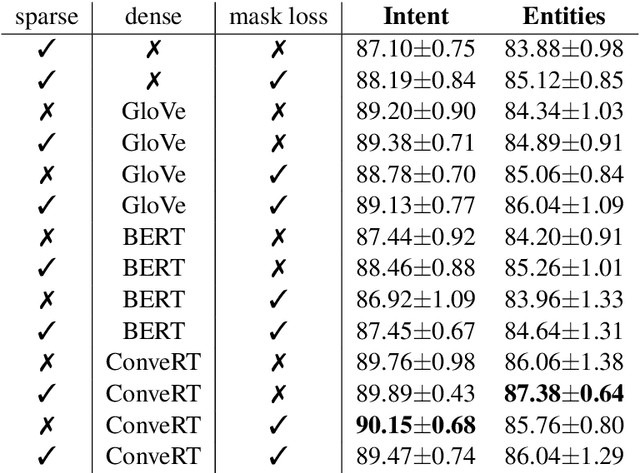
Large-scale pre-trained language models have shown impressive results on language understanding benchmarks like GLUE and SuperGLUE, improving considerably over other pre-training methods like distributed representations (GloVe) and purely supervised approaches. We introduce the Dual Intent and Entity Transformer (DIET) architecture, and study the effectiveness of different pre-trained representations on intent and entity prediction, two common dialogue language understanding tasks. DIET advances the state of the art on a complex multi-domain NLU dataset and achieves similarly high performance on other simpler datasets. Surprisingly, we show that there is no clear benefit to using large pre-trained models for this task, and in fact DIET improves upon the current state of the art even in a purely supervised setup without any pre-trained embeddings. Our best performing model outperforms fine-tuning BERT and is about six times faster to train.
Where is the context? -- A critique of recent dialogue datasets
Apr 22, 2020

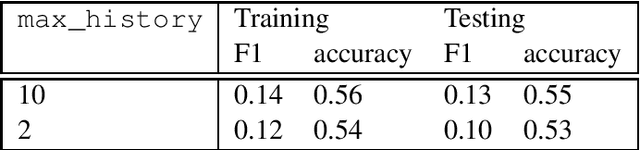
Recent dialogue datasets like MultiWOZ 2.1 and Taskmaster-1 constitute some of the most challenging tasks for present-day dialogue models and, therefore, are widely used for system evaluation. We identify several issues with the above-mentioned datasets, such as history independence, strong knowledge base dependence, and ambiguous system responses. Finally, we outline key desiderata for future datasets that we believe would be more suitable for the construction of conversational artificial intelligence.
Dialogue Transformers
Oct 01, 2019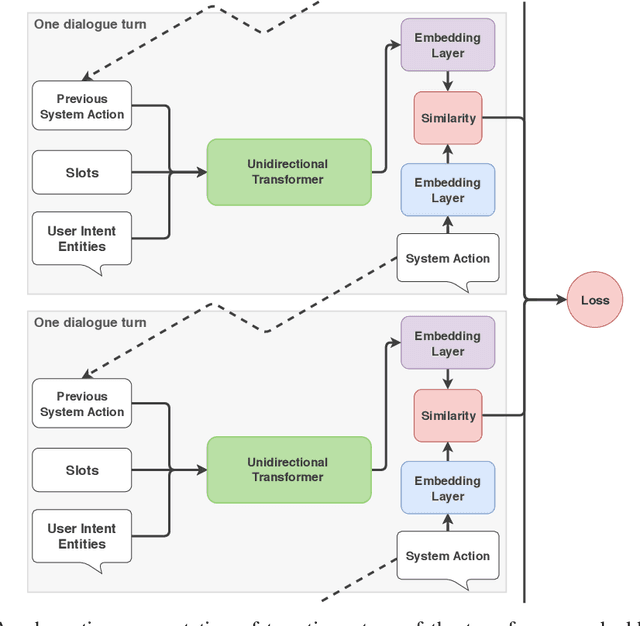


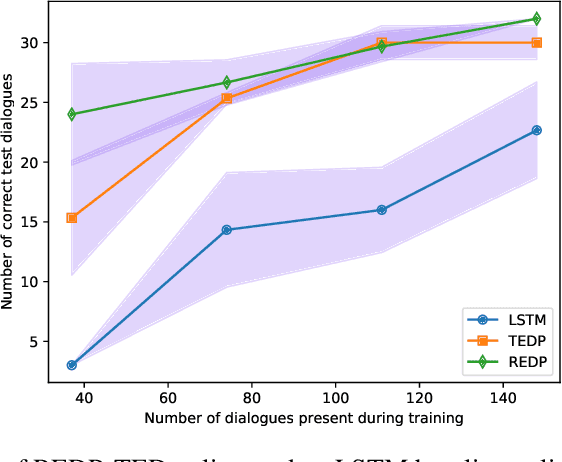
We introduce a dialogue policy based on a transformer architecture, where the self-attention mechanism operates over the sequence of dialogue turns. Recent work has used hierarchical recurrent neural networks to encode multiple utterances in a dialogue context, but we argue that a pure self-attention mechanism is more suitable. By default, an RNN assumes that every item in a sequence is relevant for producing an encoding of the full sequence, but a single conversation can consist of multiple overlapping discourse segments as speakers interleave multiple topics. A transformer picks which turns to include in its encoding of the current dialogue state, and is naturally suited to selectively ignoring or attending to dialogue history. We compare the performance of the Transformer Embedding Dialogue (TED) policy to an LSTM and to the REDP, which was specifically designed to overcome this limitation of RNNs. We show that the TED policy's behaviour compares favourably, both in terms of accuracy and speed.
Few-Shot Generalization Across Dialogue Tasks
Nov 28, 2018
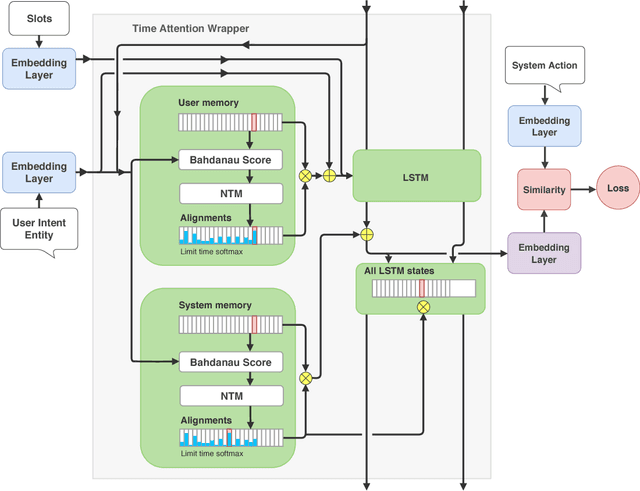
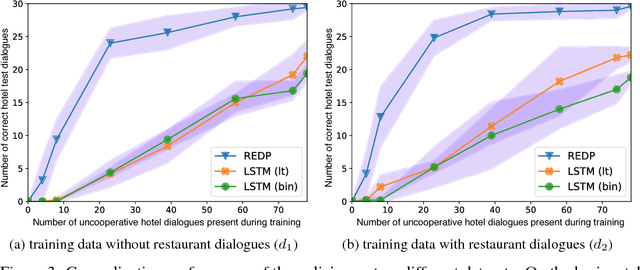
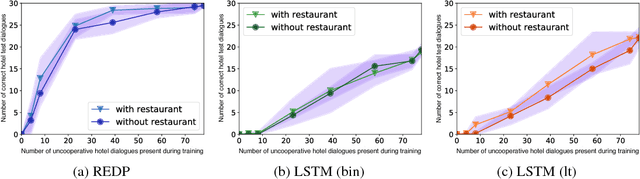
Machine-learning based dialogue managers are able to learn complex behaviors in order to complete a task, but it is not straightforward to extend their capabilities to new domains. We investigate different policies' ability to handle uncooperative user behavior, and how well expertise in completing one task (such as restaurant reservations) can be reapplied when learning a new one (e.g. booking a hotel). We introduce the Recurrent Embedding Dialogue Policy (REDP), which embeds system actions and dialogue states in the same vector space. REDP contains a memory component and attention mechanism based on a modified Neural Turing Machine, and significantly outperforms a baseline LSTM classifier on this task. We also show that both our architecture and baseline solve the bAbI dialogue task, achieving 100% test accuracy.
Rasa: Open Source Language Understanding and Dialogue Management
Dec 15, 2017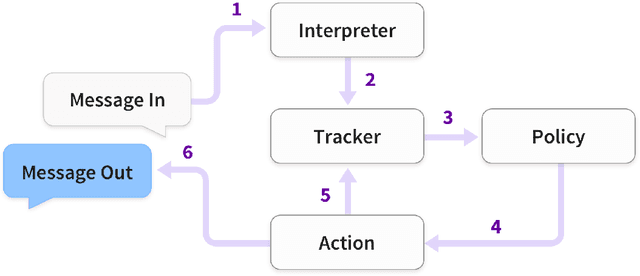
We introduce a pair of tools, Rasa NLU and Rasa Core, which are open source python libraries for building conversational software. Their purpose is to make machine-learning based dialogue management and language understanding accessible to non-specialist software developers. In terms of design philosophy, we aim for ease of use, and bootstrapping from minimal (or no) initial training data. Both packages are extensively documented and ship with a comprehensive suite of tests. The code is available at https://github.com/RasaHQ/