 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Dialogue with In-Context Learning
Feb 19, 2024


We describe a system for building task-oriented dialogue systems combining the in-context learning abilities of large language models (LLMs) with the deterministic execution of business logic. LLMs are used to translate between the surface form of the conversation and a domain-specific language (DSL) which is used to progress the business logic. We compare our approach to the intent-based NLU approach predominantly used in industry today. Our experiments show that developing chatbots with our system requires significantly less effort than established approaches, that these chatbots can successfully navigate complex dialogues which are extremely challenging for NLU-based systems, and that our system has desirable properties for scaling task-oriented dialogue systems to a large number of tasks. We make our implementation available for use and further study.
DIET: Lightweight Language Understanding for Dialogue Systems
May 11, 2020
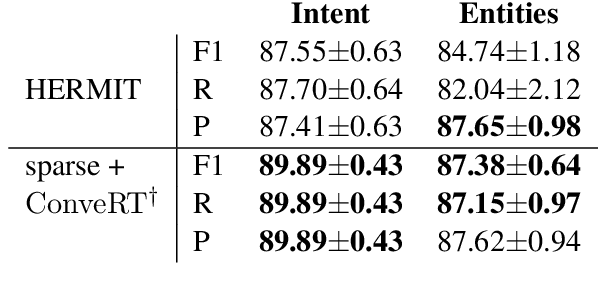

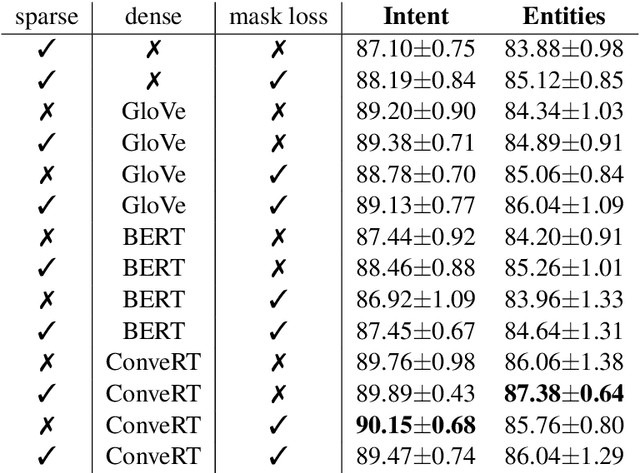
Large-scale pre-trained language models have shown impressive results on language understanding benchmarks like GLUE and SuperGLUE, improving considerably over other pre-training methods like distributed representations (GloVe) and purely supervised approaches. We introduce the Dual Intent and Entity Transformer (DIET) architecture, and study the effectiveness of different pre-trained representations on intent and entity prediction, two common dialogue language understanding tasks. DIET advances the state of the art on a complex multi-domain NLU dataset and achieves similarly high performance on other simpler datasets. Surprisingly, we show that there is no clear benefit to using large pre-trained models for this task, and in fact DIET improves upon the current state of the art even in a purely supervised setup without any pre-trained embeddings. Our best performing model outperforms fine-tuning BERT and is about six times faster to train.
Human Trajectory Prediction using Spatially aware Deep Attention Models
May 26, 2017
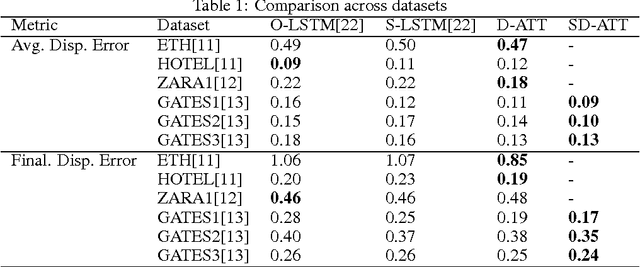


Trajectory Prediction of dynamic objects is a widely studied topic in the field of artificial intelligence. Thanks to a large number of applications like predicting abnormal events, navigation system for the blind, etc. there have been many approaches to attempt learning patterns of motion directly from data using a wide variety of techniques ranging from hand-crafted features to sophisticated deep learning models for unsupervised feature learning. All these approaches have been limited by problems like inefficient features in the case of hand crafted features, large error propagation across the predicted trajectory and no information of static artefacts around the dynamic moving objects. We propose an end to end deep learning model to learn the motion patterns of humans using different navigational modes directly from data using the much popular sequence to sequence model coupled with a soft attention mechanism. We also propose a novel approach to model the static artefacts in a scene and using these to predict the dynamic trajectories. The proposed method, tested on trajectories of pedestrians, consistently outperforms previously proposed state of the art approaches on a variety of large scale data sets. We also show how our architecture can be naturally extended to handle multiple modes of movement (say pedestrians, skaters, bikers and buses) simultaneously.