 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Generalization Across Dialogue Tasks
Paper and Code
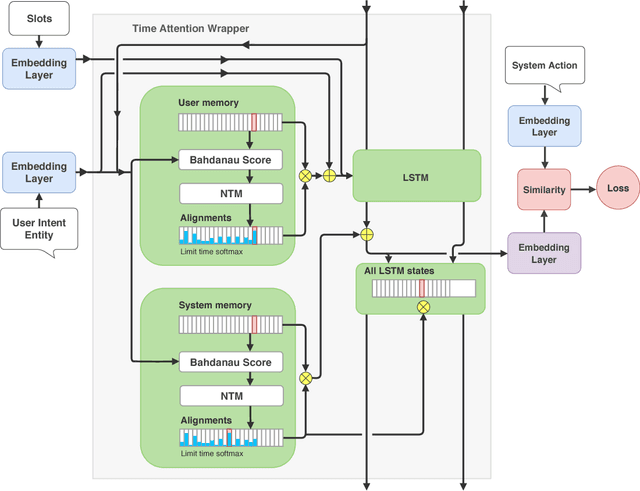
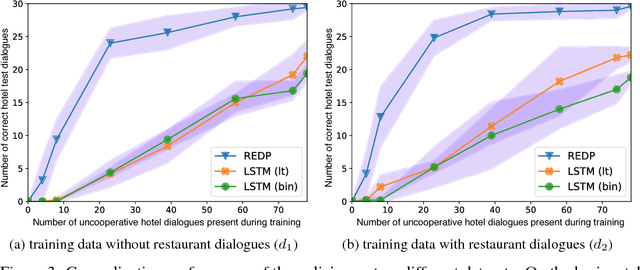
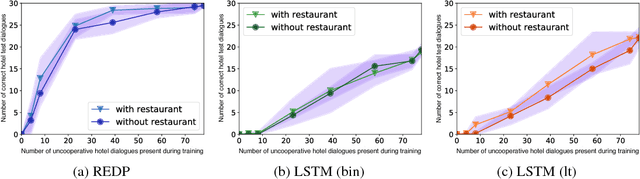
Machine-learning based dialogue managers are able to learn complex behaviors in order to complete a task, but it is not straightforward to extend their capabilities to new domains. We investigate different policies' ability to handle uncooperative user behavior, and how well expertise in completing one task (such as restaurant reservations) can be reapplied when learning a new one (e.g. booking a hotel). We introduce the Recurrent Embedding Dialogue Policy (REDP), which embeds system actions and dialogue states in the same vector space. REDP contains a memory component and attention mechanism based on a modified Neural Turing Machine, and significantly outperforms a baseline LSTM classifier on this task. We also show that both our architecture and baseline solve the bAbI dialogue task, achieving 100% test accuracy.