Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic TM Cleaning through MT and POS Tagging: Autodesk's Submission to the NLP4TM 2016 Shared Task
May 19, 2016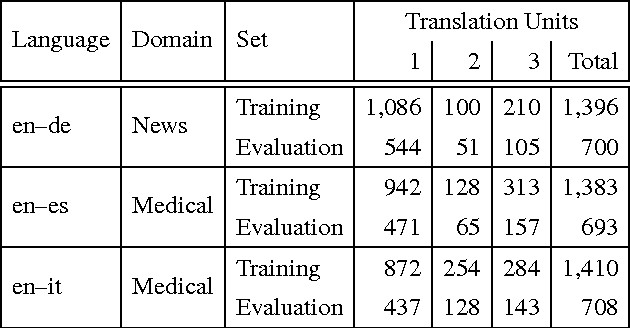
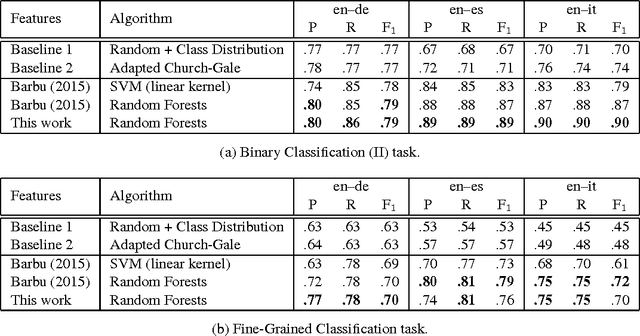
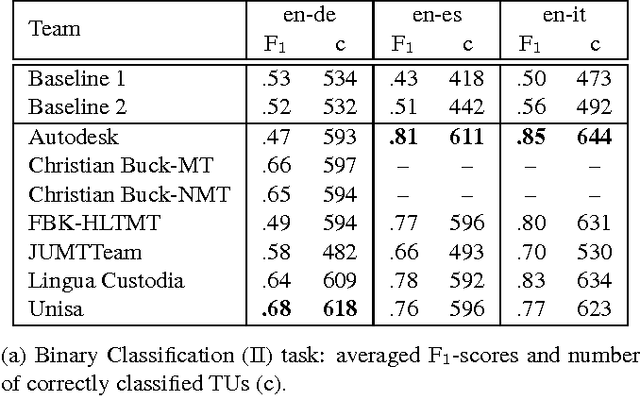
We describe a machine learning based method to identify incorrect entries in translation memories. It extends previous work by Barbu (2015) through incorporating recall-based machine translation and part-of-speech-tagging features. Our system ranked first in the Binary Classification (II) task for two out of three language pairs: English-Italian and English-Spanish.
* Presented at the 2nd Workshop on Natural Language Processing for
Translation Memories (NLP4TM 2016)
Via