 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Edinburgh International Accents of English Corpus: Towards the Democratization of English ASR
Mar 31, 2023English is the most widely spoken language in the world, used daily by millions of people as a first or second language in many different contexts. As a result, there are many varieties of English. Although the great many advances in English automatic speech recognition (ASR) over the past decades, results are usually reported based on test datasets which fail to represent the diversity of English as spoken today around the globe. We present the first release of The Edinburgh International Accents of English Corpus (EdAcc). This dataset attempts to better represent the wide diversity of English, encompassing almost 40 hours of dyadic video call conversations between friends. Unlike other datasets, EdAcc includes a wide range of first and second-language varieties of English and a linguistic background profile of each speaker. Results on latest public, and commercial models show that EdAcc highlights shortcomings of current English ASR models. The best performing model, trained on 680 thousand hours of transcribed data, obtains an average of 19.7% word error rate (WER) -- in contrast to the 2.7% WER obtained when evaluated on US English clean read speech. Across all models, we observe a drop in performance on Indian, Jamaican, and Nigerian English speakers. Recordings, linguistic backgrounds, data statement, and evaluation scripts are released on our website (https://groups.inf.ed.ac.uk/edacc/) under CC-BY-SA license.
Language technology practitioners as language managers: arbitrating data bias and predictive bias in ASR
Feb 25, 2022Despite the fact that variation is a fundamental characteristic of natural language, automatic speech recognition systems perform systematically worse on non-standardised and marginalised language varieties. In this paper we use the lens of language policy to analyse how current practices in training and testing ASR systems in industry lead to the data bias giving rise to these systematic error differences. We believe that this is a useful perspective for speech and language technology practitioners to understand the origins and harms of algorithmic bias, and how they can mitigate it. We also propose a re-framing of language resources as (public) infrastructure which should not solely be designed for markets, but for, and with meaningful cooperation of, speech communities.
Querent Intent in Multi-Sentence Questions
Oct 18, 2020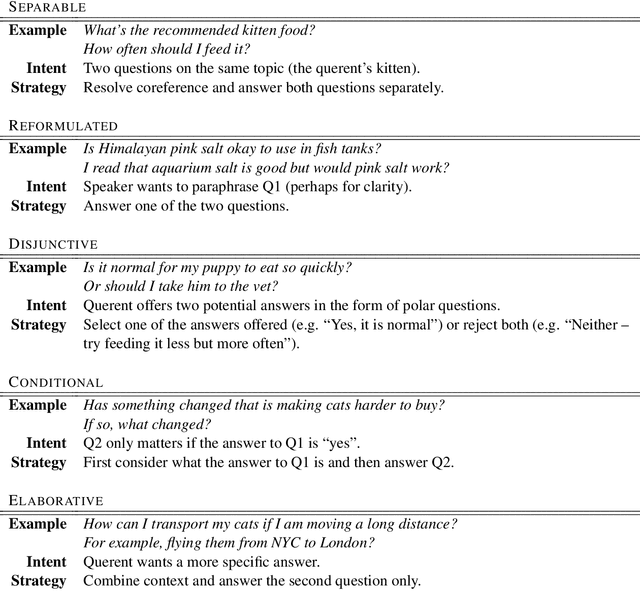
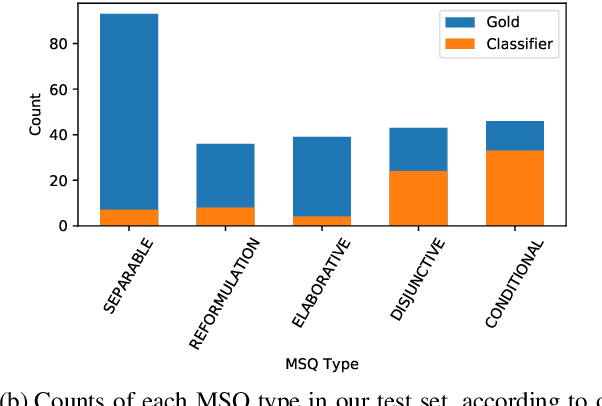
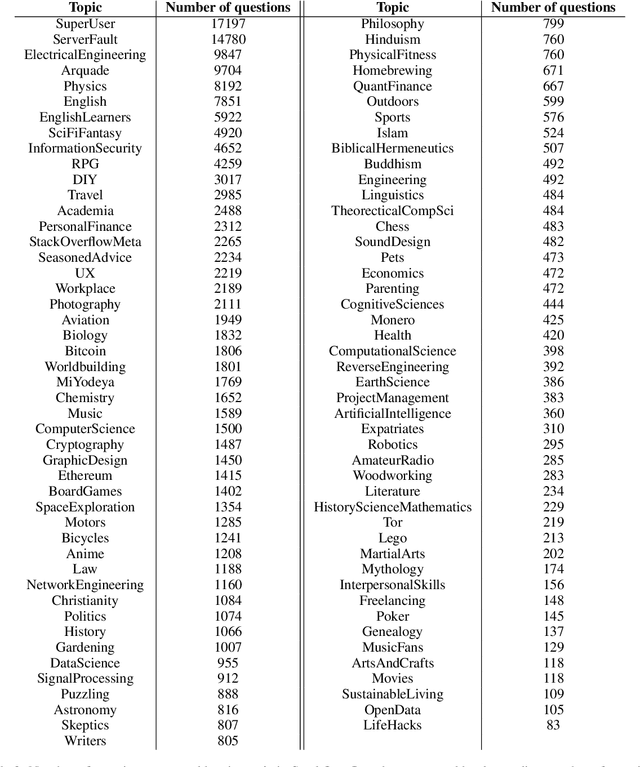

Multi-sentence questions (MSQs) are sequences of questions connected by relations which, unlike sequences of standalone questions, need to be answered as a unit. Following Rhetorical Structure Theory (RST), we recognise that different "question discourse relations" between the subparts of MSQs reflect different speaker intents, and consequently elicit different answering strategies. Correctly identifying these relations is therefore a crucial step in automatically answering MSQs. We identify five different types of MSQs in English, and define five novel relations to describe them. We extract over 162,000 MSQs from Stack Exchange to enable future research. Finally, we implement a high-precision baseline classifier based on surface features.