 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Diversity in Back Translation for Low-Resource Machine Translation
Paper and Code
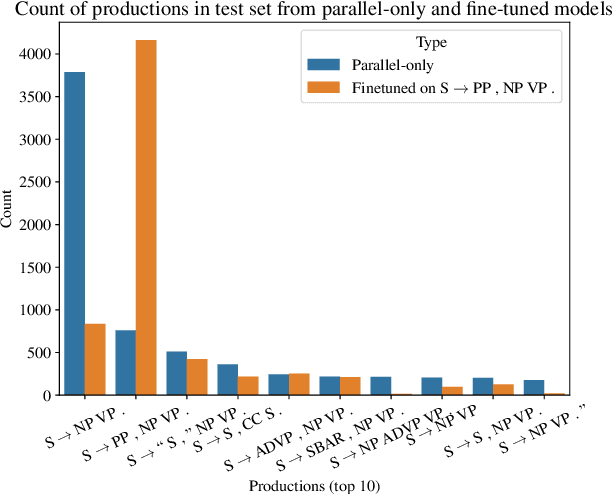
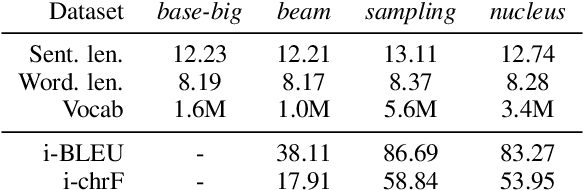
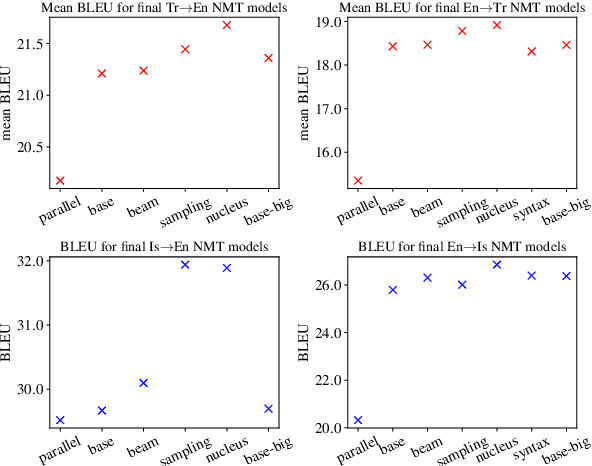
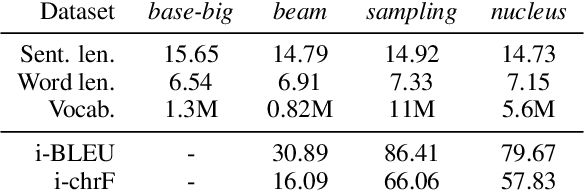
Back translation is one of the most widely used methods for improving the performance of neural machine translation systems. Recent research has sought to enhance the effectiveness of this method by increasing the 'diversity' of the generated translations. We argue that the definitions and metrics used to quantify 'diversity' in previous work have been insufficient. This work puts forward a more nuanced framework for understanding diversity in training data, splitting it into lexical diversity and syntactic diversity. We present novel metrics for measuring these different aspects of diversity and carry out empirical analysis into the effect of these types of diversity on final neural machine translation model performance for low-resource English$\leftrightarrow$Turkish and mid-resource English$\leftrightarrow$Icelandic. Our findings show that generating back translation using nucleus sampling results in higher final model performance, and that this method of generation has high levels of both lexical and syntactic diversity. We also find evidence that lexical diversity is more important than syntactic for back translation performance.