 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the Left Foot Leads to the Right Path: Bridging Initial Prejudice and Trainability
May 17, 2025



Understanding the statistical properties of deep neural networks (DNNs) at initialization is crucial for elucidating both their trainability and the intrinsic architectural biases they encode prior to data exposure. Mean-field (MF) analyses have demonstrated that the parameter distribution in randomly initialized networks dictates whether gradients vanish or explode. Concurrently, untrained DNNs were found to exhibit an initial-guessing bias (IGB), in which large regions of the input space are assigned to a single class. In this work, we derive a theoretical proof establishing the correspondence between IGB and previous MF theories, thereby connecting a network prejudice toward specific classes with the conditions for fast and accurate learning. This connection yields the counter-intuitive conclusion: the initialization that optimizes trainability is necessarily biased, rather than neutral. Furthermore, we extend the MF/IGB framework to multi-node activation functions, offering practical guidelines for designing initialization schemes that ensure stable optimization in architectures employing max- and average-pooling layers.
Where You Place the Norm Matters: From Prejudiced to Neutral Initializations
May 16, 2025Normalization layers, such as Batch Normalization and Layer Normalization, are central components in modern neural networks, widely adopted to improve training stability and generalization. While their practical effectiveness is well documented, a detailed theoretical understanding of how normalization affects model behavior, starting from initialization, remains an important open question. In this work, we investigate how both the presence and placement of normalization within hidden layers influence the statistical properties of network predictions before training begins. In particular, we study how these choices shape the distribution of class predictions at initialization, which can range from unbiased (Neutral) to highly concentrated (Prejudiced) toward a subset of classes. Our analysis shows that normalization placement induces systematic differences in the initial prediction behavior of neural networks, which in turn shape the dynamics of learning. By linking architectural choices to prediction statistics at initialization, our work provides a principled understanding of how normalization can influence early training behavior and offers guidance for more controlled and interpretable network design.
Producing Plankton Classifiers that are Robust to Dataset Shift
Jan 25, 2024Modern plankton high-throughput monitoring relies on deep learning classifiers for species recognition in water ecosystems. Despite satisfactory nominal performances, a significant challenge arises from Dataset Shift, which causes performances to drop during deployment. In our study, we integrate the ZooLake dataset with manually-annotated images from 10 independent days of deployment, serving as test cells to benchmark Out-Of-Dataset (OOD) performances. Our analysis reveals instances where classifiers, initially performing well in In-Dataset conditions, encounter notable failures in practical scenarios. For example, a MobileNet with a 92% nominal test accuracy shows a 77% OOD accuracy. We systematically investigate conditions leading to OOD performance drops and propose a preemptive assessment method to identify potential pitfalls when classifying new data, and pinpoint features in OOD images that adversely impact classification. We present a three-step pipeline: (i) identifying OOD degradation compared to nominal test performance, (ii) conducting a diagnostic analysis of degradation causes, and (iii) providing solutions. We find that ensembles of BEiT vision transformers, with targeted augmentations addressing OOD robustness, geometric ensembling, and rotation-based test-time augmentation, constitute the most robust model, which we call BEsT model. It achieves an 83% OOD accuracy, with errors concentrated on container classes. Moreover, it exhibits lower sensitivity to dataset shift, and reproduces well the plankton abundances. Our proposed pipeline is applicable to generic plankton classifiers, contingent on the availability of suitable test cells. By identifying critical shortcomings and offering practical procedures to fortify models against dataset shift, our study contributes to the development of more reliable plankton classification technologies.
Initial Guessing Bias: How Untrained Networks Favor Some Classes
Jun 01, 2023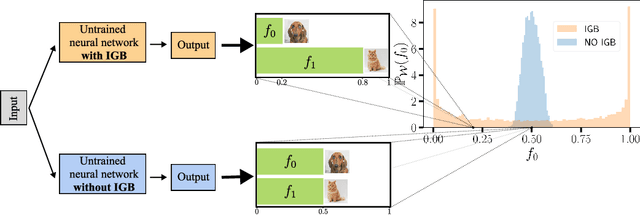
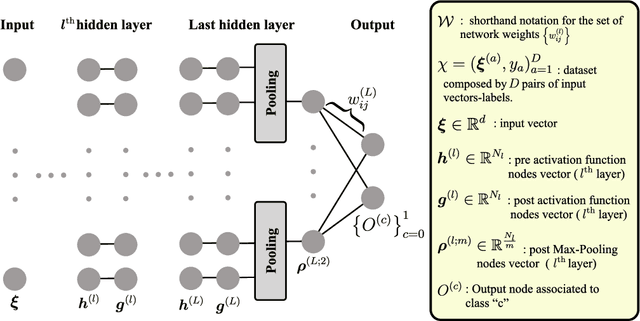


The initial state of neural networks plays a central role in conditioning the subsequent training dynamics. In the context of classification problems, we provide a theoretical analysis demonstrating that the structure of a neural network can condition the model to assign all predictions to the same class, even before the beginning of training, and in the absence of explicit biases. We show that the presence of this phenomenon, which we call "Initial Guessing Bias" (IGB), depends on architectural choices such as activation functions, max-pooling layers, and network depth. Our analysis of IGB has practical consequences, in that it guides architecture selection and initialization. We also highlight theoretical consequences, such as the breakdown of node-permutation symmetry, the violation of self-averaging, the validity of some mean-field approximations, and the non-trivial differences arising with depth.
Characterizing the Effect of Class Imbalance on the Learning Dynamics
Jul 01, 2022
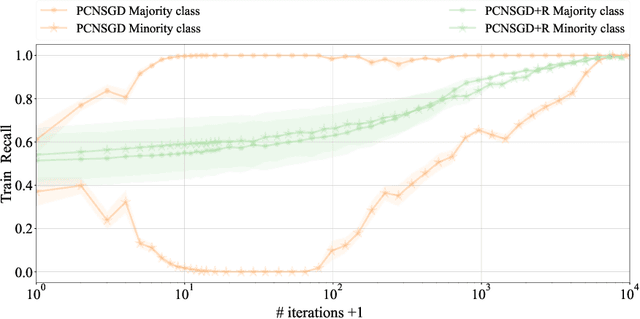
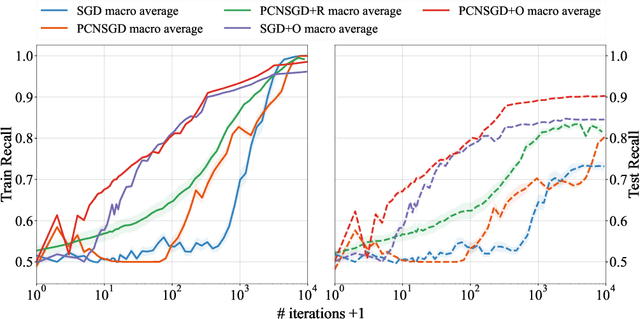
Data imbalance is a common problem in the machine learning literature that can have a critical effect on the performance of a model. Various solutions exist - such as the ones that focus on resampling or data generation - but their impact on the convergence of gradient-based optimizers used in deep learning is not understood. We here elucidate the significant negative impact of data imbalance on learning, showing that the learning curves for minority and majority classes follow sub-optimal trajectories when training with a gradient-based optimizer. The reason is not only that the gradient signal neglects the minority classes, but also that the minority classes are subject to a larger directional noise, which slows their learning by an amount related to the imbalance ratio. To address this problem, we propose a new algorithmic solution, for which we provide a detailed analysis of its convergence behavior. We show both theoretically and empirically that this new algorithm exhibits a better behavior with more stable learning curves for each class, as well as a better generalization performance.